This week, we will be focusing on point pattern analysis (PPA), which aims to detect clusters or patterns within a set of points. Through this analysis, we can measure density, dispersion, and homogeneity in point structures. Various methods exist for calculating and identifying these clusters, and today we will explore several of these techniques using our bike theft dataset from last week.
3.1 Lecture slides
The slides for this week’s lecture can be downloaded here: [Link]
3.2 Reading list
Essential readings
Arribas-Bel, D., Garcia-López, M.-À., Viladecans-Marsal, E. 2021. Building(s and) cities: Delineating urban areas with a machine learning algorithm. Journal of Urban Economics 125: 103217. [Link]
Cheshire, J. and Longley, P. 2012. Identifying spatial concentrations of surnames. International Journal of Geographical Information Science 26(2), pp.309-325. [Link]
Longley, P. et al. 2015. Geographic Information Science & systems, Chapter 12: Geovisualization. [Link]
Suggested readings
Van Dijk, J. and Longley, P. 2020. Interactive display of surnames distributions in historic and contemporary Great Britain. Journal of Maps 16, pp.58-76. [Link]
Yin, P. 2020. Kernels and density estimation. The Geographic Information Science & Technology Body of Knowledge. [Link]
3.3 Bike theft in London II
This week, we will revisit bicycle theft in London, focusing specifically on identifying patterns and clusters of theft incidents. To do this, we will use the bicycle theft dataset that we prepared last week, along with the 2021 MSOA boundaries for London. If you no longer have a copy of these files on your computer, you can download them using the links provided below.
Reading layer `London-BicycleTheft-2023' from data source
`/Users/justinvandijk/Library/CloudStorage/Dropbox/UCL/Web/jtvandijk.github.io/GEOG0030/data/spatial/London-BicycleTheft-2023.gpkg'
using driver `GPKG'
Simple feature collection with 16019 features and 10 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: 384035.6 ymin: 101574.6 xmax: 612801.1 ymax: 398089
Projected CRS: OSGB36 / British National Grid
# inspecthead(msoa21)
Simple feature collection with 6 features and 8 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 530966.7 ymin: 180512.6 xmax: 551943.8 ymax: 191139
Projected CRS: OSGB36 / British National Grid
msoa21cd msoa21nm msoa21nmw bng_e bng_n lat long
1 E02000001 City of London 001 532384 181355 51.51562 -0.093490
2 E02000002 Barking and Dagenham 001 548267 189685 51.58652 0.138756
3 E02000003 Barking and Dagenham 002 548259 188520 51.57606 0.138149
4 E02000004 Barking and Dagenham 003 551004 186412 51.55639 0.176828
5 E02000005 Barking and Dagenham 004 548733 186824 51.56069 0.144267
6 E02000007 Barking and Dagenham 006 549698 186609 51.55851 0.158087
globalid geom
1 {71249043-B176-4306-BA6C-D1A993B1B741} MULTIPOLYGON (((532135.1 18...
2 {997A80A8-0EBE-461C-91EB-3E4122571A6E} MULTIPOLYGON (((548881.6 19...
3 {62DED9D9-F53A-454D-AF35-04404D9DBE9B} MULTIPOLYGON (((549102.4 18...
4 {511181CD-E71F-4C63-81EE-E8E76744A627} MULTIPOLYGON (((551550.1 18...
5 {B0C823EB-69E0-4AE7-9E1C-37715CF3FE87} MULTIPOLYGON (((549099.6 18...
6 {A33C6ADD-D70A-4737-ADE5-3460D7016CA1} MULTIPOLYGON (((549819.9 18...
# inspecthead(theft_bike)
Simple feature collection with 6 features and 10 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: 531274.9 ymin: 180967.9 xmax: 533333.7 ymax: 181781.7
Projected CRS: OSGB36 / British National Grid
crime_id month
1 62b0f525fc471c062463ec87469c71e133cdd1c39a09e2bc5ec50c0cbbdd650a 2023-01
2 9a078d630cf67c37c9e47b5904149d553697931d920eec993f358a637fbf6186 2023-01
3 f175a32ef7f90c67a5cb83c268ad793e4ce7e0ae19e52b57d213805e65651bdd 2023-01
4 137ec1201fd64b57898d3558fe3b8000182442e957efc28246797ea61065c86b 2023-01
5 4c3b467755a98afa3d3c82b526307750ddad9ec13598aaa68130b76863e112cb 2023-01
6 13b5eb5ca0aef09a222221fbab8da799d55b5a65716f1bbb7cc96e36aebdc816 2023-01
reported_by falls_within location
1 City of London Police City of London Police On or near
2 City of London Police City of London Police On or near
3 City of London Police City of London Police On or near Lombard Street
4 City of London Police City of London Police On or near Mitre Street
5 City of London Police City of London Police On or near Temple Avenue
6 City of London Police City of London Police On or near Montague Street
lsoa_code lsoa_name crime_type
1 E01000002 City of London 001B Bicycle theft
2 E01032739 City of London 001F Bicycle theft
3 E01032739 City of London 001F Bicycle theft
4 E01032739 City of London 001F Bicycle theft
5 E01032740 City of London 001G Bicycle theft
6 E01032740 City of London 001G Bicycle theft
last_outcome_category context
1 Investigation complete; no suspect identified NA
2 Investigation complete; no suspect identified NA
3 Investigation complete; no suspect identified NA
4 Investigation complete; no suspect identified NA
5 Investigation complete; no suspect identified NA
6 Investigation complete; no suspect identified NA
geom
1 POINT (532390.8 181781.7)
2 POINT (532157.8 181196.8)
3 POINT (532720.7 181087.8)
4 POINT (533333.7 181219.8)
5 POINT (531274.9 180967.9)
6 POINT (531956.8 181624.8)
You can further inspect both objects using the View() function.
3.3.1 Point aggregation
One key advantage of point data is that it is scale-free, allowing aggregation to any geographic level for analysis. Before diving into PPA, we will aggregate the bicycle thefts to the MSOA level to map their distribution by using a point-in-polygon approach.
R code
# point in polygonmsoa21 <- msoa21 |>mutate(theft_bike_n =lengths(st_intersects(msoa21, theft_bike, sparse =TRUE)))
To create a point-in-polygon count within sf, we use the st_intersects() function and keep its default sparse = TRUE output, which produces a list of intersecting points by index for each polygon (e.g. MSOA). We then apply the lengths() function to count the number of points intersecting each polygon, giving us the total number of bike thefts per MSOA.
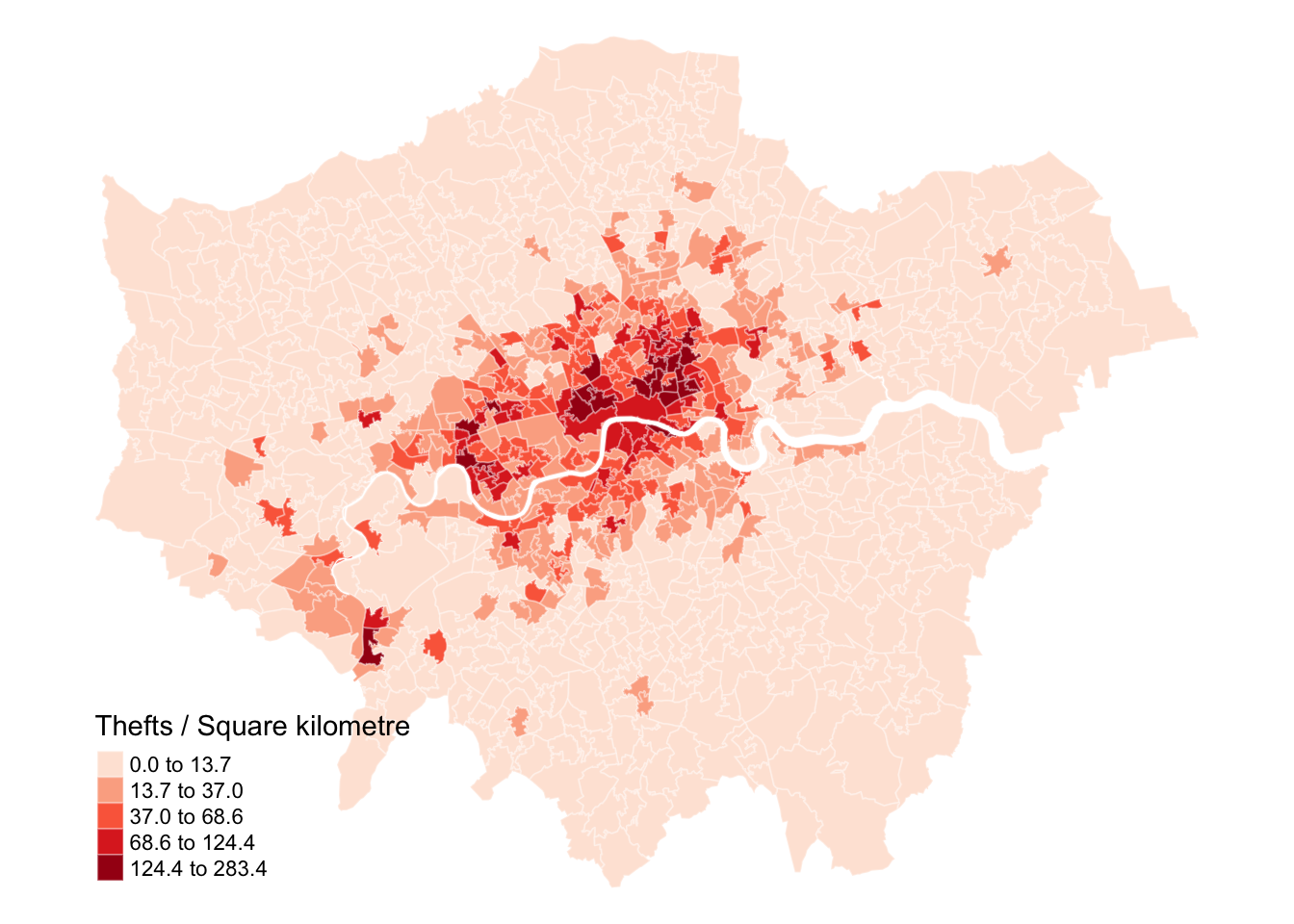
We can now calculate the area of each MSOA and, combined with the total number of bicycle thefts, determine the number of thefts per square kilometre. This involves calculating the size of each MSOA in square kilometres and then dividing the total number of thefts by this area to get a theft density measure.
Figure 1: Number of reported bicycle thefts by square kilometre.
3.3.2 Point pattern analysis
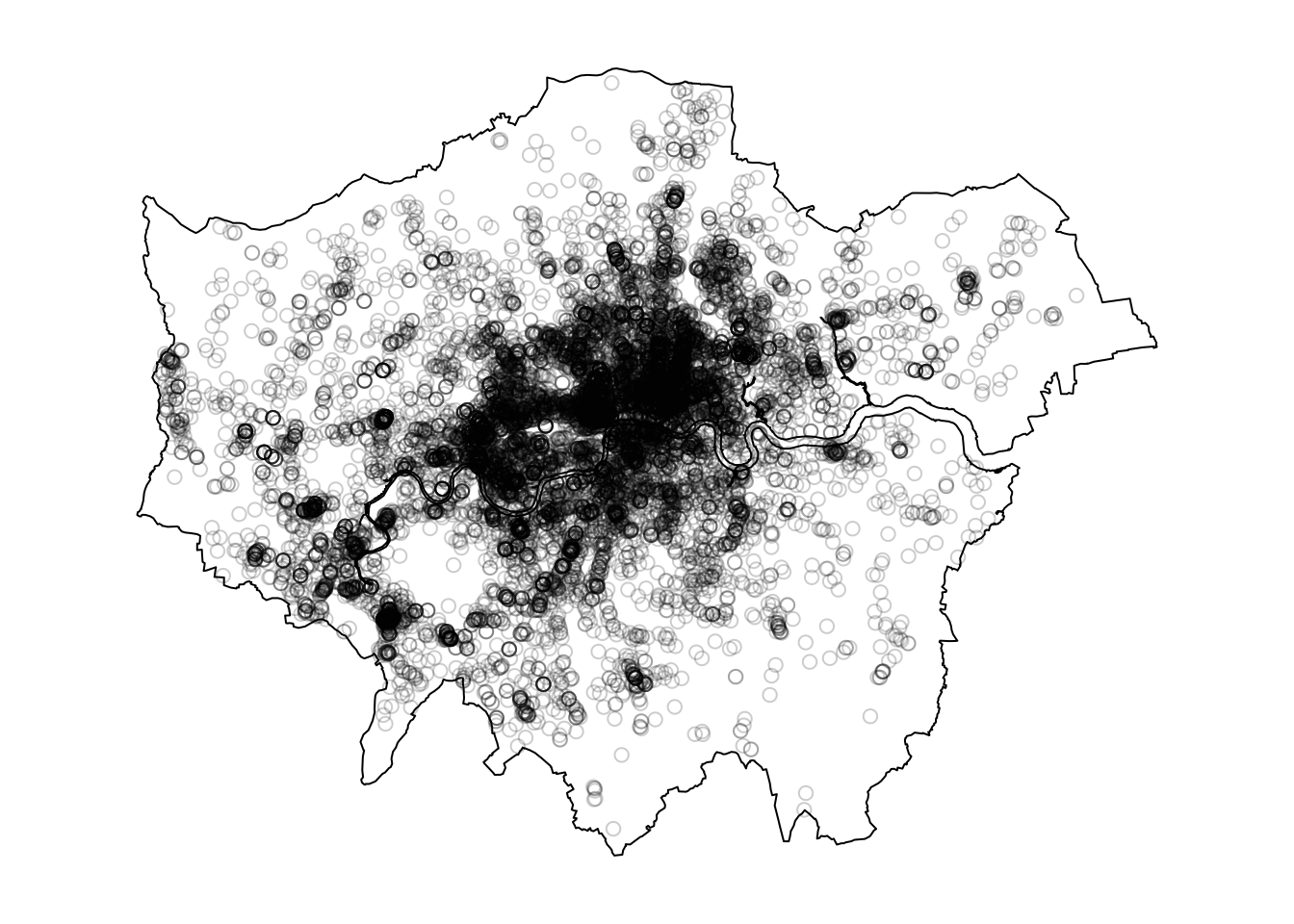
Figure 1 shows that the number of bicycle thefts is clearly concentrated in parts of Central London. While this map may provide helpful insights, its representation depends on the classification and aggregation of the underlying data. Alternatively, we can directly analyse the point events themselves. For this, we will use the spatstat library, the primary library for point pattern analysis in R. To use spatstat, we need to convert our data into a ppp object.
The ppp format is specific to spatstat but is also used in some other spatial analysis libraries. A ppp object represents a two-dimensional point dataset within a defined area, called the window of observation (owin in spatstat). We can either create a ppp object directly from a list of coordinates (with a specified window of observation) or convert it from another data type.
We can turn our theft_bike dataframe into a ppp object as follows:
R code
# london outlineoutline <- msoa21 |>st_union()# cliptheft_bike <- theft_bike |>st_intersection(outline)
Warning: attribute variables are assumed to be spatially constant throughout
all geometries
# sf to pppwindow =as.owin(msoa21)theft_bike_ppp <-ppp(st_coordinates(theft_bike)[, 1], st_coordinates(theft_bike)[,2], window = window)
Warning: data contain duplicated points
# inspectpar(mar =c(1, 1, 1, 1))plot(theft_bike_ppp, main ="")
Figure 2: Bike theft in London represented as ppp object.
Some statistical procedures require point events to be unique. In our bicycle theft data, duplicates are likely due to the police snapping points to protect anonymity and privacy. This can pose an issue for spatial point pattern analysis, where each theft and its location must be distinct. We can check whether we have any duplicated points as follows:
R code
# check for duplicatesanyDuplicated(theft_bike_ppp)
[1] TRUE
# count number of duplicated pointssum(multiplicity(theft_bike_ppp) >1)
[1] 10003
To address this, we have three options:
Remove duplicates if the number of duplicated points is small or the exact location is less important than the overall distribution.
Assign weights to points, where each has an attribute indicating the number of events at that location rather than being recorded as separate event.
Add jitter by slightly offsetting the points randomly, which can be useful if precise location is not crucial for the analysis.
Each approach has its own trade-offs, depending on the analysis. In our case, we will use the jitter approach to retain all bike theft events. Since the locations are already approximated, adding a small offset (~5 metre) will not impact the analysis.
# count number of duplicated pointssum(multiplicity(theft_bike_jitter) >1)
[1] 0
This seemed to have worked, so we can move forward.
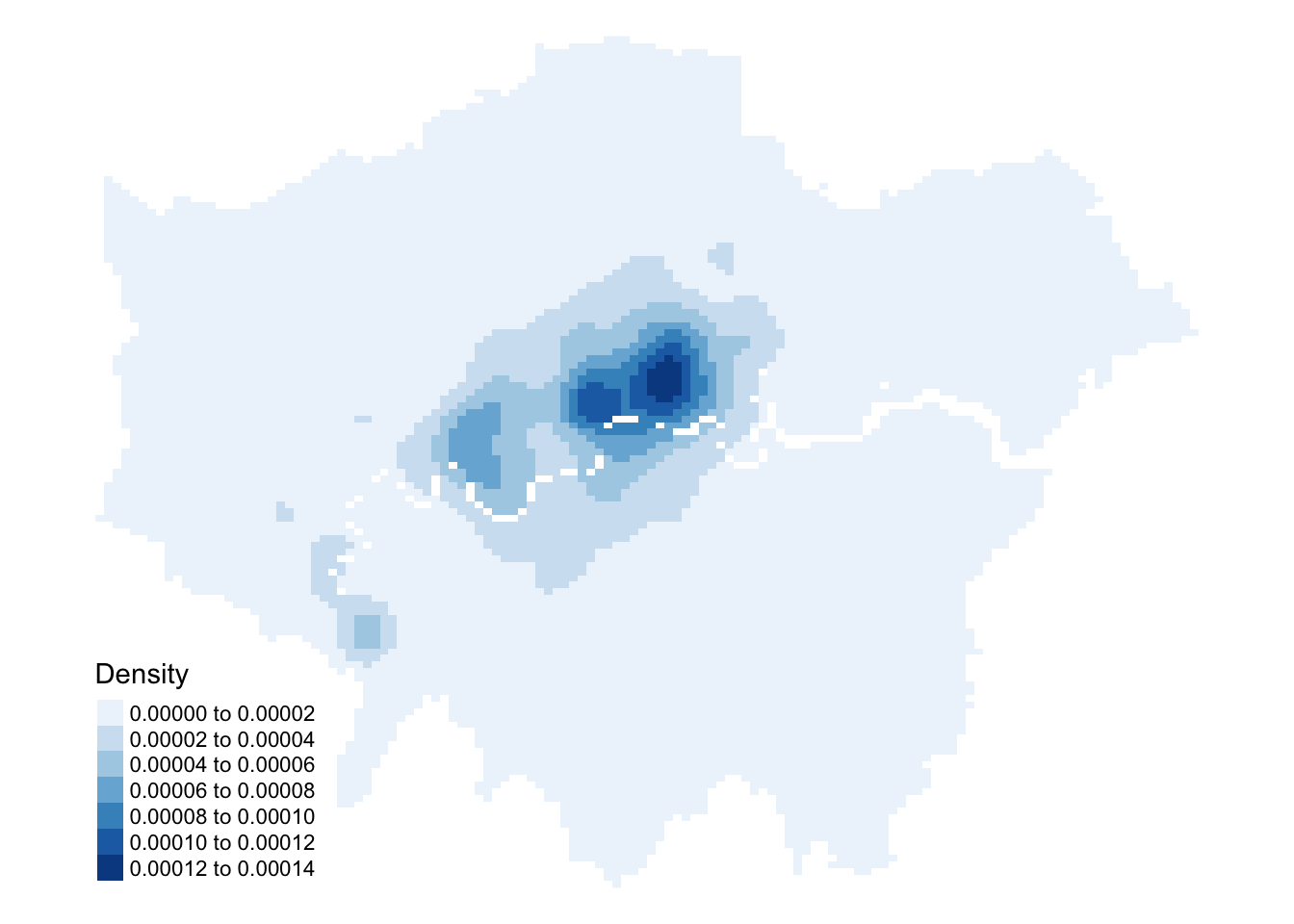
3.3.2.1 Kernel density estimation
Instead of visualising the distribution of bike thefts at a specific geographical level, we can use Kernel Density Estimation (KDE) to display the distribution of these incidents. KDE is a statistical method that creates a smooth, continuous distribution to represent the density of the underlying pattern between data points.
Kernel Density Estimation (KDE) generates a raster surface that shows the estimated density of event points across space. Each cell represents the local density, highlighting areas of high or low concentration. KDE uses overlapping moving windows (defined by a kernel) and a bandwidth parameter, which controls the size of the window, influencing the smoothness of the resulting density surface. The kernel function can assign equal or weighted values to points, producing a grid of density values based on these local calculations.
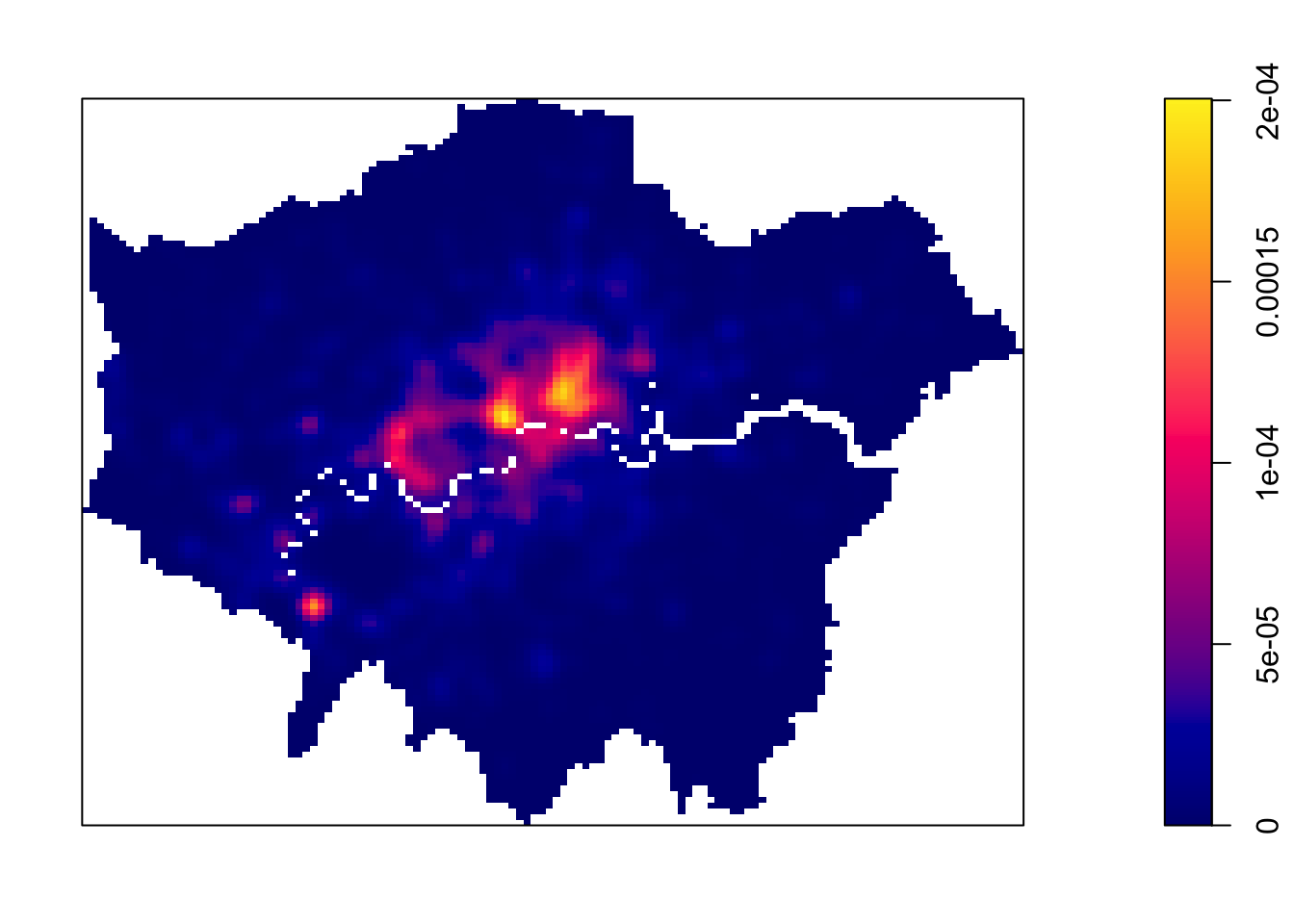
Let’s go ahead and create a simple KDE of bike theft with our bandwidth set to 500 metres:
R code
# kernel density estimationpar(mar =c(1, 1, 1, 1))plot(density.ppp(theft_bike_jitter, sigma =500), main ="")
Figure 3: Kernel density estimation - bandwidth 500m.
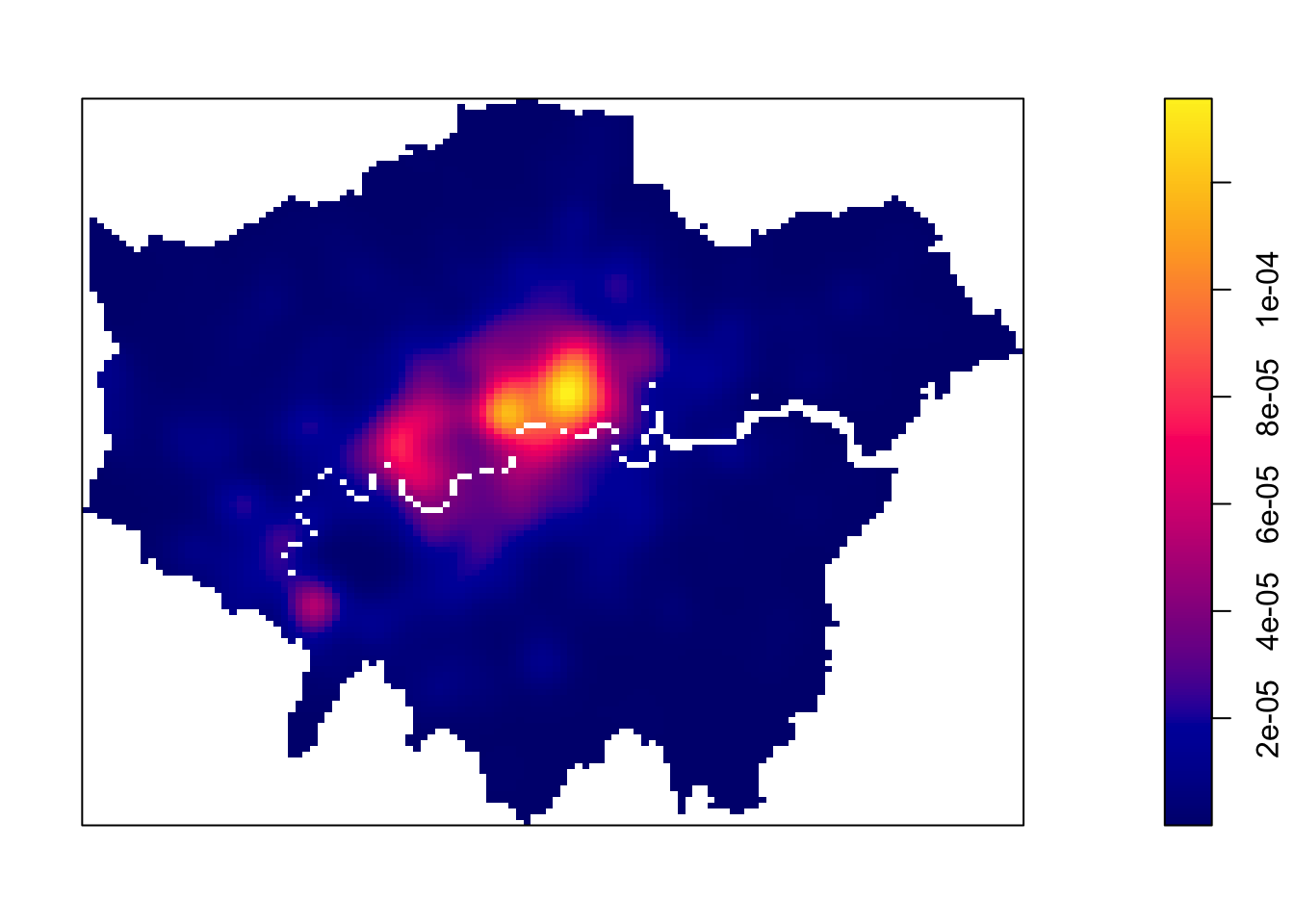
We can see from just our KDE that there are visible clusters present within our bike theft data, particularly in and around Central London. We can go ahead and increase the bandwidth to to see how that affects the density estimate:
R code
# kernel density estimationpar(mar =c(1, 1, 1, 1))plot(density.ppp(theft_bike_jitter, sigma =1000), main ="")
Figure 4: Kernel density estimation - bandwidth 1000m.
By increasing the bandwidth, our clusters appear larger and brighter than with the 500-metre bandwidth. A larger bandwidth considers more points, resulting in a smoother surface. However, this can lead to oversmoothing, where clusters become less defined, potentially overestimating areas of high bike theft. Smaller bandwidths offer more precision and sharper clusters but risk undersmoothing, which can cause irregularities.
While automated methods (e.g. maximum-likelihood estimation) can assist in selecting an optimal bandwidth, the choice is subjective and depends on the specific characteristics of your dataset.
Although bandwidth has a greater impact on density estimation than the kernel type, the choice of kernel can still influence the results by altering how points are weighted within the window. We will explore kernel types a little further when we discuss spatial models in a few weeks time.
Once we are satisfied with our KDE visualisation, we can create a proper map by converting the KDE output into raster format.
R code
# to rastertheft_bike_raster <-density.ppp(theft_bike_jitter, sigma =1000) |>rast()
We now have a standalone raster that we can use with any function in the tmap library. However, one issue is that the resulting raster lacks a Coordinate Reference System (CRS), so we need to manually assign this information to the raster object:
Figure 5: Kernel Density Estimate of bicycle thefts in London.
The values of the KDE output are stored in the raster grid as lyr.1.
3.3.2.2 DBSCAN
Kernel Density Estimation is a useful exploratory technique for identifying spatial clusters in point data, but it does not provide precise boundaries for these clusters. To more accurately delineate clusters, we can use an algorithm called DBSCAN (Density-Based Spatial Clustering of Applications with Noise), which takes both distance and density into account. DBSCAN is effective at discovering distinct clusters by grouping together points that are close to one another while marking points that don’t belong to any cluster as noise.
DBSCAN requires two parameters:
Parameter
Description
epsilon
The maximum distance for points to be considered in the same cluster.
minPts
The minimum number of points for a cluster.
The algorithm groups nearby points based on these parameters and marks low-density points as outliers. DBSCAN is useful for uncovering patterns that are difficult to detect visually, but it works best when clusters have consistent densities.
Let us try this with an epsilon of 200 metres and minPts of 20 bicycle thefts:
The dbscan() function accepts a data matrix or dataframe of points, not a spatial dataframe. That is why, in the code above, we use the st_coordinates() function to extract the projected coordinates from the spatial dataframe.
The DBSCAN output includes three objects, one of which is a vector detailing the cluster each bike theft observation has been assigned to. To work with this output effectively, we need to add the cluster labels back to the original point dataset. Since DBSCAN does not alter the order of points, we can simply add the cluster output to the theft_bike spatial dataframe.
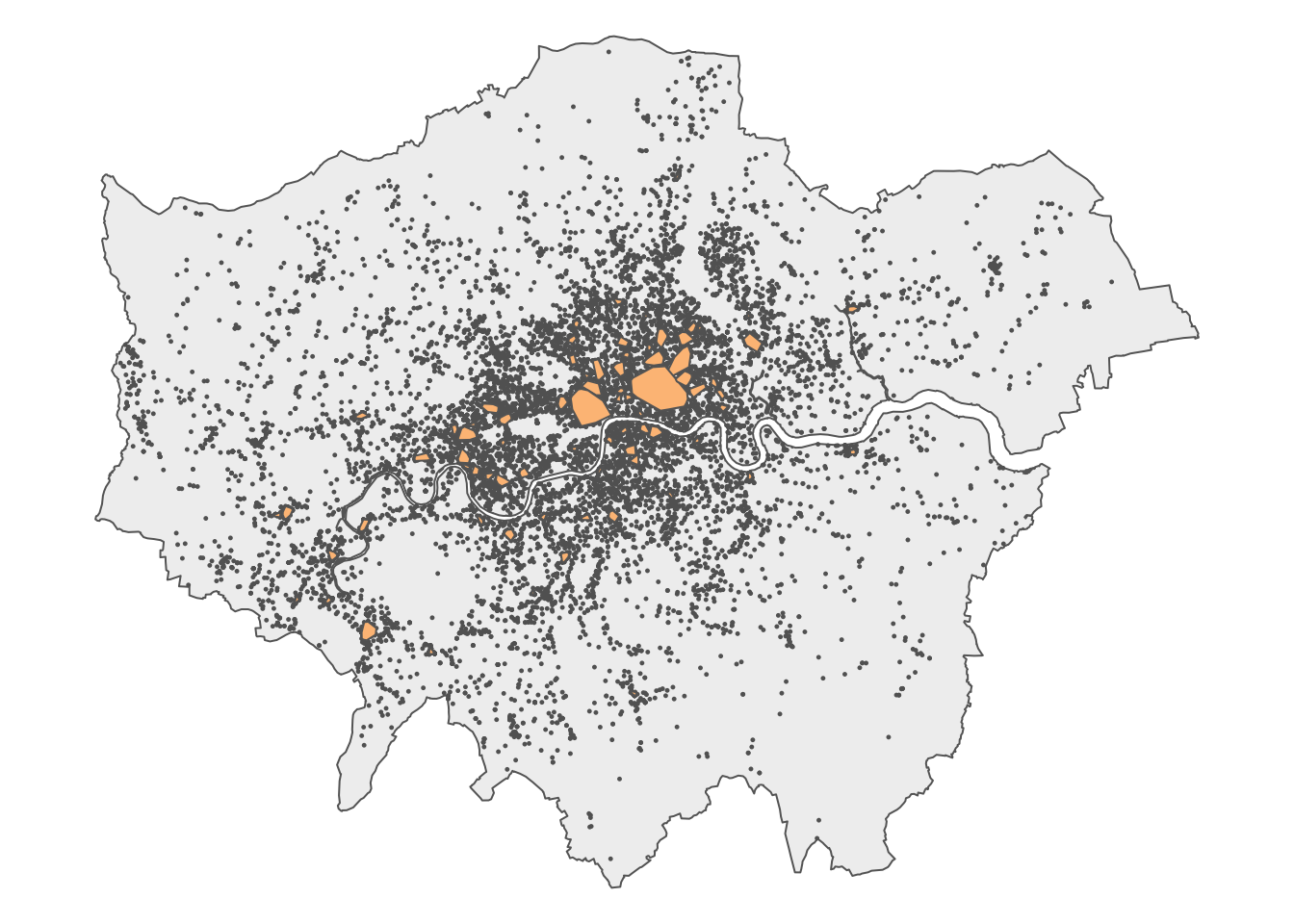
Now that each bike theft point in London is associated with a specific cluster, where appropriate, we can generate a polygon representing these clusters. To do this, we will use the st_convex_hull() function from the sf package, which creates a polygon that covers the minimum bounding area of a collection of points. We will apply this function to each cluster using a for loop, which allows us to repeat the process for each group of points and create a polygon representing the geometry of each cluster.
R code
# create an empty list to store the resulting convex hull geometries set the# length of this list to the total number of clusters foundgeometry_list <-vector(mode ="list", length =max(theft_bike$dbcluster))# begin loopfor (cluster_index inseq(1, max(theft_bike$dbcluster))) {# filter to only return points for belonging to cluster n theft_bike_subset <- theft_bike |>filter(dbcluster == cluster_index)# union points, calculate convex hull cluster_polygon <- theft_bike_subset |>st_union() |>st_convex_hull()# add the geometry of the polygon to our list geometry_list[cluster_index] <- (cluster_polygon)}# combine the listtheft_bike_clusters <-st_sfc(geometry_list, crs =27700)
While loops in R should generally be avoided for large datasets due to inefficiency, they remain a useful tool for automating repetitive tasks and reducing the risk of errors. For smaller datasets or tasks that cannot easily be vectorised, loops can still be effective and simplify the code.
We now have a spatial dataframe that contains the bike theft clusters in London, as defined by the DBSCAN clustering algorithm. Let’s quickly map these clusters:
Figure 6: DBSCAN-identified clusters of reported bicycle theft in London.
3.4 Assignment
Now that we know how to work with point locatoin data, we can again apply a similar analysis to road crashes in London in 2022 that we used last week. This time we will use this dataset to assess whether road crashes cluster in specific areas. Try the following:
Create a Kernel Density Estimation (KDE) of all road crashes that occurred in London in 2022.
Using DBSCAN output, create a cluster map of serious and fatal road crashes in London
If you no longer have a copy of the 2022 London STATS19 Road Collision dataset, you can download it using the link provided below.
With access to point event data, geographers aim to identify underlying patterns. This week, we explored several techniques that help us analyse and interpret such data. That is us done for this week. Reading list anyone?