2 GIScience and GIS software
This week’s lecture introduced you to foundational concepts associated with GIScience and GIS software, with particular emphasis on the representation of spatial data and sample design. Out of all our foundational concepts you will come across in the next four weeks, this is probably the most substantial to get to grips with and has both significant theoretical and practical aspects to its learning. The practical component of the week puts some of these learnings into practice, starting with a short digitisation excercise followed by a simple visualisation of London’s population over time.
2.1 Lecture slides
The slides for this week’s lecture can be downloaded here: [Link].
2.2 Reading list
Essential readings
- Longley, P. et al. 2015. Geographic Information Science & Systems, Chapter 2: The Nature of Geographic Data. [Link]
- Longley, P. et al. 2015. Geographic Information Science & Systems, Chapter 3: Representing Geography. [Link]
- Longley, P. et al. 2015. Geographic Information Science & Systems, Chapter 7: Geographic Data Modeling. [Link]
Suggested readings
- Goodchild, M. and Haining, R. 2005. GIS and spatial data analysis: Converging perspectives. Papers in Regional Science 83(1): 363–385. [Link]
- Schurr, C., Müller, M. and Imhof, N. 2020. Who makes geographical knowledge? The gender of Geography’s gatekeepers. The Professional Geographer 72(3): 317-331. [Link]
- Yuan, M. 2001. Representing complex geographic phenomena in GIS. Cartography and Geographic Information Science 28(2): 83-96. [Link]
2.3 Simple digitisation of spatial features
To get spatial features in a digital form, they need to be digitised. Let’s take what should be a straight-forward example of digitising the River Thames in London.
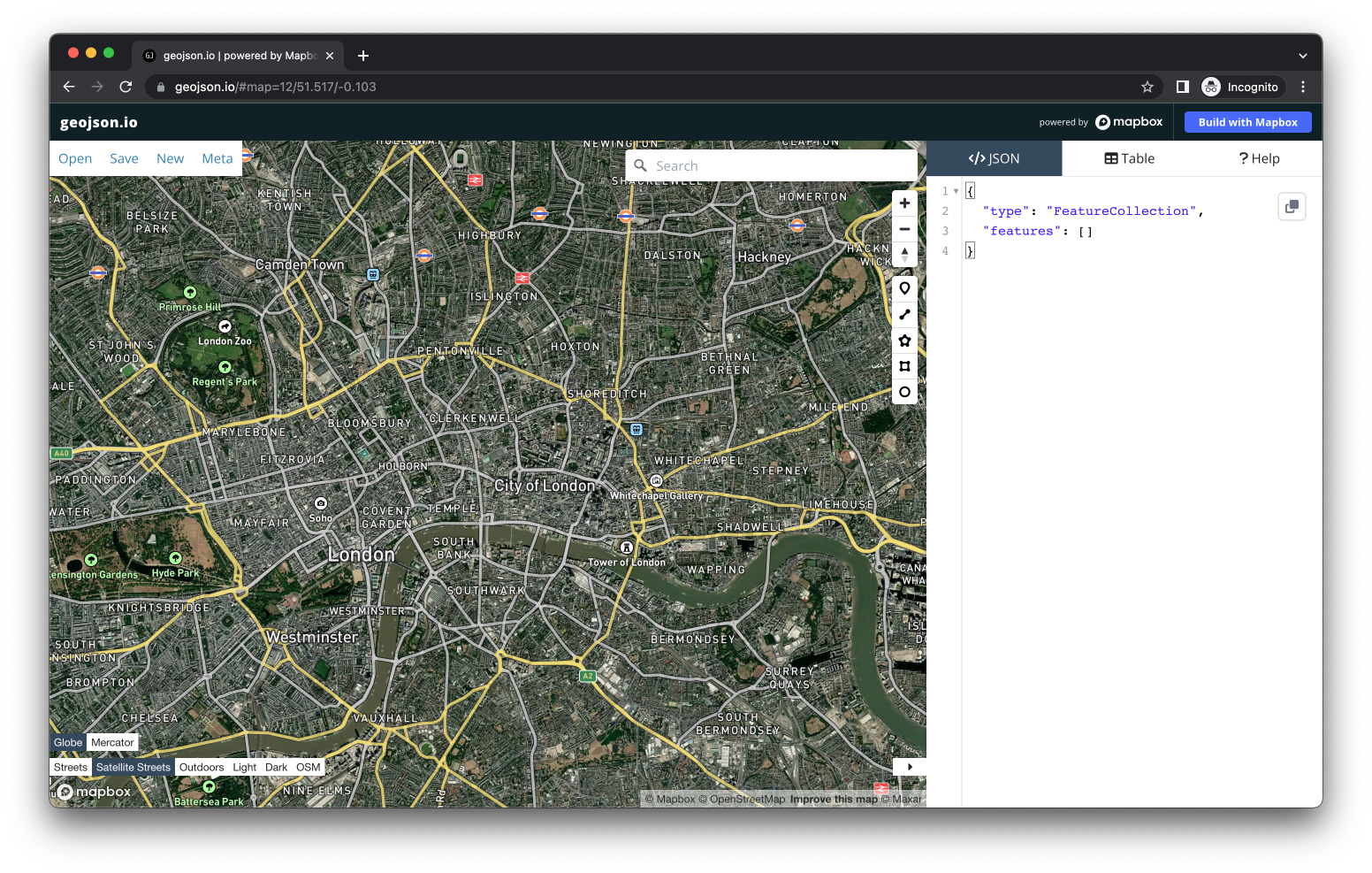
Figure 2.1: The Thames.
We are going to use a very simple online tool that allows us to create digital data and export the data we create as raw files.
- Head to geojson.io.
- In the bottom left-hand corner, select Satellite Streets as your map option.
- Next, click on the
Draw Linestringtool which you can find on the right hand side of the screen. You can hover over the icons to get the names of each tool. - Now digitise the river Thames. Simply click from a starting point on the left- or right-hand side of the map, and digitise the river.
- Once you are done, double-click your final point to end your line.
- You can click on the line and select Info in the pop-up screen to find out how long the line is.
- You can export your data using the Save menu.
Questions
- How easy did you find it to digitise the data and what decisions did you make in your own “sample scheme”?
- How close together are your clicks between lines?
- Did you sacrifice detail over expediency or did you spend perhaps a little too long trying to capture ever small bend in the river?
- How well do you think your line represents the River Thames?
2.4 Population change in London
The second part of this practical will introduces you to attribute joins followed by creating a choropleth map. You will be using different types of joins throughout this module, and probably the rest of your career, so it is incredibly important that you understand how they work.
Note
The datasets you will create in this practical will be used in next week’s practical, so make sure to follow every step and save your data carefully.
When using spatial data, there is generally a very specific workflow that you will need to go through and, believe it or not, the majority of this is not actually focused on analysing your data. Along with the idea that 80% of data is geographic data, the second most often-quoted GIS-related unreferenced ‘fact’ is that anyone working with spatial data will spend 80% of their time simply finding, retrieving, managing and processing the data before any analysis can be done.
One of the reasons behind this need for a substantial amount of processing is that the data you often need to use is almost never in the format that you require for analysis. For example, for our investigation, there is not a ‘ready-made’ spatial population dataset (i.e. population shapefile) we can download to explore population change across England:
Figure 2.2: Alas a quick Google search shows that finding a shapefile of England’s population is not straightforward.
Instead, we need to go and find the raw datasets and create the data layers that we want. As a result, before beginning any spatial analysis project, it is best-practice to think through what end product you will ultimately need for your analysis.
A typical spatial analysis workflow usually looks something like this:
- Identify the data you need to complete your analysis i.e. answer your research questions. This includes thinking through the scale, coverage and currency of your dataset.
- Find the data that matches your requirements, e.g. is it openly and easily available?
- Download the data and store it in the correct location.
- Clean the data. This may be done before or after ingesting your data into your chosen software programme.
- Load the data into your chosen software programme.
- Transform and process the data. This may require re-projection, creating joins between datasets, calculating new fields and applying selections.
- Analyse your data using appropriate methods.
- Visualise your data and results with graphs and maps.
- Communicate your results.
As you can see, the analysis and visualisation part comes quite late in the overall spatial analysis workflow - and instead, the workflow is very top-heavy with data management. However, very often in GIS-related courses you will be given pre-processed datasets. Because data management is an essential part of your workflow, we are clean (the majority of) our data from the get-go. This will help you understand the processes that you will need to go through in the future as you search for and download your own data, as well as deal with the data first-hand before loading it into our GIS software.
2.4.1 Setting the scene
For this practical, we will investigate how the population in London has changed over time. Understanding population change - over time and space - is spatial analysis at its most fundamental. We can understand a lot just from where population is growing or decreasing, including thinking through the impacts of these changes on the provision of housing, education, health and transport infrastructure.
We can also see first-hand the impact of wider socio-economic processes, such as urbanisation. Today we will look at population in London in 2011, 2015, and 2019 at the Ward scale that we can use within our future analysis projects, starting next week.
Note
We will use the population dataset to normalise other datasets. Why? When we record events created by humans, there is often a population bias: simply, more people in an area will by probability lead to a higher occurrence of said event, such as crime. We will look at this in greater detail next week.
2.4.2 Finding data
In the UK, finding authoritative data on population and Administrative Geography boundaries is increasingly straight-forward. Over the last decade, the UK government has opened up many of its datasets as part of an Open Data precedent that began in 2010 with the creation of data.gov.uk and the Open Government Licence (the terms and conditions for using data).
Data.gov.uk is the UK government’s central database that contains open data that the central government, local authorities and public bodies publish. This includes, for example, aggregated census and health data – and even government spending. In addition to this central database, there are other authoritative databases run by the government and/or respective public bodies that contain either a specific type of data (e.g. census data, crime data) or a specific collection of datasets (e.g. health data from the NHS, data about London). Some portals are less up-to-date than others, so it is wise to double-check with the ‘originators’ of the data to see if there are more recent versions.
For our practical, we will access data from two portals:
- For our administrative boundaries, we will download the spatial data from the London Datastore (which is exactly what it sounds like).
- For population, we will download attribute data from the Office of National Statistics (ONS).
2.4.3 Housekeeping
Before we download our data, it is important to establish an organised file systems that we will use throughout the module:
- Create a
GEOG0030folder in yourDocumentsfolder on your computer. - Within your
GEOG0030folder, create the following subfolders:
| Folder name | Purpose |
|---|---|
data |
To store both raw data sets and final outputs. |
maps |
To save the maps you produce during your tutorials. |
- Within your
datafolder, create the following subfolders:
| Folder name | Purpose |
|---|---|
raw |
To store all your raw data files that have not yet been processed. |
output |
To store all your final data files that have been processed and analysed, potentially ready to be mapped. |
2.4.4 Downloading data
We will start by downloading the administrative geography boundaries:
- Navigate to the relevant page on the London Datastore: [Link].
- Download all three zipfiles to your computer:
statistical-gis-boundaries-london.zip,London-wards-2014.zipandLondon-wards-2018.zip.
The first dataset contains all levels of London’s administrative boundaries. In descending size order: Borough, Ward, Middle layer Super Output Area (MSOA), Lower layer Super Output Area (LSOA), and Output Area (OA) based on the 2011 Census. The second dataset contains an updated version of the Ward boundaries, as of 2014. The third dataset contains yet another updated version of the Ward boundaries, as of 2018. As we will be looking at population data for 2015 and 2019, it is best practice to use those boundaries that are most reflective of the ‘geography’ at the time; therefore, we will use these 2014 / 2018 Ward boundaries for our 2015 / 2019 population dataset, respectively.
Tip
Once downloaded, you will need to unzip all files before you can use them. To unzip the file, you can use the built-in functionality of your computer’s operating system. For Windows: right click on the zip file, select Extract All, and then follow the instructions. For Mac OS: double-click on the the zip file and it should unzip automatically.
Once unzipped, you will find two folders: Esri and MapInfo. These folders contain the same data but in different data formats: Esri shapefile and MapInfo TAB.
Note
MapInfo is another proprietary GIS software, which has historically been used in public sectors services in the UK and abroad, although has generally been replaced by either Esri’s ecosystem or open-source software GIS.
Now open your GEOG0030/data/raw/ folder and create a new folder called boundaries. Within this folder, create three new folders: 2011, 2014 and 2018. Copy the entire contents of Esri folder of each year into their respective year folder.
We do not want to add the additional Esri folder as a step in our filesystem, i.e. your file paths should read: GEOG0030/data/raw/boundaries/2011 for the 2011 boundaries, GEOG0030/data/raw/boundaries/2014 for the 2014 boundaries, and GEOG0030/data/raw/boundaries/2018 for the 2018 boundaries.
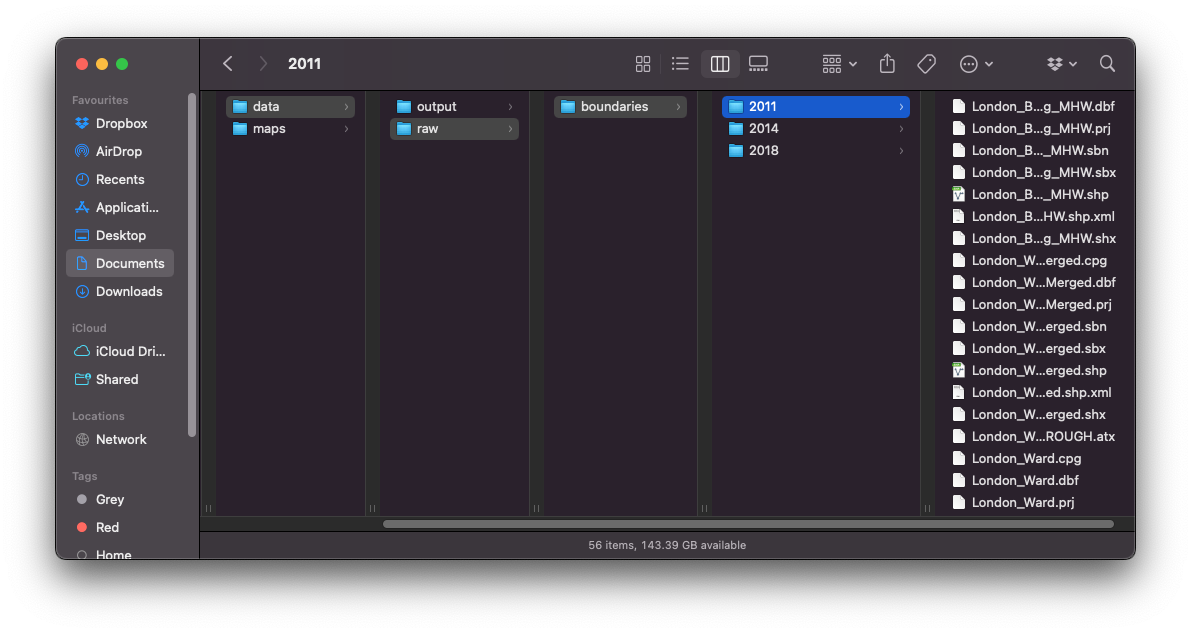
Figure 2.3: Your setup should look something like this.
We now have our administrative geography files ready for use.
Note
Administrative geographies are a way of dividing the country into smaller sub-divisions or areas that correspond with the area of responsibility of local authorities and government bodies. These administrative sub-divisions and their associated geography have several important uses, including assigning electoral constituencies, defining jurisdiction of courts, planning public healthcare provision, as well as what we are concerned with: used as a mechanism for collecting census data and assigning the resulting datasets to a specific administrative unit. These geographies are updated as populations evolve and as a result, the boundaries of the administrative geographies are subject to either periodic or occasional change. The UK has quite a complex administrative geography, particularly due to having several countries within one overriding administration and then multiple ways of dividing the countries according to specific applications. More details on the administrative geographies of the UK can be found on the website of the Office for National Statistics.
For our population datasets, we will use the ONS mid-year estimates (MYE). These population datasets are estimates that are based on the 2011 census count and then updated with estimated population growth. They are released once a year, with a delay of a year. Today we will use the data for 2011, 2015, and 2019.
- Navigate to the Ward level datasets: [Link]
- When you navigate to this page, you will find multiple choices of data to download. We will need to download the estimates for 2011, 2015 and 2019. Click to download each of the zipfiles. Choose the revised versions for 2015 and the (Census-based) 2011 Wards edition for 2011.
- In your
GEOG0030/data/raw/folder, create a new folder calledpopulation, unzip your downloaded files, and copy the three spreadsheets to the newly createdpopulationfolder. - Rename the files you donwloaded to:
MYE_ward_2011.xls,MYE_ward_2015.xls, andMYE_ward_2019.xlsx.
Now it is time to do some quite extensive data cleaning and preparation.
2.4.5 Cleaning data
When you open up any of the Ward spreadsheets in Excel =, you will notice that there are several worksheets contained in this workbook. However, we are only interested in the total population tab. We therefore need to copy over the data from the 2011, 2015 and 2019 datasets into separate csv files.
2.4.5.1 London population in 2011
- Open the 2011 Ward spreadsheet in Excel.
- Click on the
Mid-2011 Personstab and have a look at the data. As you should be able to see, we have a set of different fields (e.g.Ward Code,Ward Name), including population counts. Because we do not need all the data in the spreadsheet, we will extract only the data we need for our analysis. This means we need the total population (All Ages) data, alongside some identifying information that distinguishes each record from one another. Here we can see that bothWard CodeandWard Namesuit this requirement. We can also think that theLocal Authoritycolumn might be of use, so we also keep this information. - Create a new Excel spreadsheet Excel and from the
Mid-2011 Personsspreadsheet, copy over all cells from columns A to D and rows 4 to 636 into this new spreadsheet. Row 636 denotes the end of the Greater London Wards (i.e. the end of the Westminster Local Authority) which are kept (in most scenarios) at the top of the spreadsheet as their Ward Codes are the first in sequential order. - Before we go any further, we need to format our data. First, we want to rename our fields to remove the spaces and superscript formatting. Re-title the fields as follows:
ward_code,ward_name,local_authorityandpop2011. - One further bit of formatting that you must do before saving your data is to format our population field. At the moment, you will see that there are commas separating the thousands within our values. If we leave these commas in our values, QGIS will read them as decimal points, creating decimal values of our population. There are many points at which we could solve this issue, but the easiest point is now - we will strip our population values of the commas and set them to integer (whole numbers) values. To format the
pop2011column, select the entire column and right-click on theDcell. Click on Format Cells and set the Cells to Number with 0 decimal places. You should see that the commas are now removed from your population values. - Save your spreadsheet into your
outputfolder asward_population_2011.csv.
2.4.5.2 London population in 2015
- Open the 2015 Ward spreadsheet in Excel.
- As you will see again, there are plenty of worksheets available and we want to select the
Mid-2015 Personstab. We now need to copy over the data from our 2015 dataset to a new spreadsheet again. However, at first instance, you will notice that the City of London (CoL) Wards are missing from this dataset. Then if you scroll to the end of the London Local Authorities, i.e. to the bottom of Westminster, what you should notice is that the final row for the Westminster data is in fact row 575 - this suggests we are missing the data fror some Local Authorities (LAs). We need to determine which ones are missing and try to find them in the 2015 spreadsheet. With this in mind, start by copying over all cells from columns A to D and rows 5 to 575 into a new spreadsheet. - If you were to compare the names of the London Boroughs that we have now copied with the full list, you would notice that we are missing City of London, Hackney, Kensington and Chelsea, and Tower Hamlets. If we head back to the original 2015 raw dataset, we can actually find this data (as well as the City of London) further down in the spreadsheet. It seems like these LAs had their codes revised in the 2014 revision and are no longer in the same order as the 2011 dataset.
- Locate the data for the City of London, Hackney, Kensington and Chelsea and Tower Hamlets and copy this over into our new spreadsheet. Double-check that you now have in total 637 Wards within your dataset.
- Remember to rename the fields as above, but change your population field to pop2015. Also, remember to reformat the values in your
pop2015column. - Once complete, save your spreadsheet into your
outputfolder asward_population_2015.csv.
2.4.5.3 London population in 2019
- Open the 2019 Ward spreadsheet in Excel. This time we are interested in the
Mid-2019 Personstab. - This time the data that we are interested in can be found in columns
A,B,DandG. Because the columns that we want are not positioned next to one another, start by hiding columnsC,EandF. You can do this by right-clicking on the colums you want to hide and selecting Hide. - Next, copy the data from row 5 to the final row for the Westminster data for columns
A,B,DandGover into a new spreadsheet. - If you look at the total rows that we have copied over, we have even fewer Wards than the 2015 dataset. This time we are not only missing data for City of London, Hackney, Kensington and Chelsea, Tower Hamlets but also for Bexley, Croydon, Redbridge, and Southwark.
- Copy over the remaining Wards for these Local Authorities/Boroughs.
- Once you’ve copied them over - you should now have 640 Wards. Delete columns
C,EandFand rename the remaining fields as you have done previously. Also, remember to reformat the values in yourpop2019column. - Once complete, save your spreadsheet into your
outputfolder asward_population_2019.csv.
You should now have your three population csv datasets in your output folder. We are now (finally) ready to start using our data within QGIS.
2.4.6 Using QGIS to map our population data
2.4.6.1 Setting up a project
We will now use QGIS to create population maps for the Wards in London across our three time periods. To achieve this, we need to join our table data to our spatial datasets and then map our populations for our visual analysis.
Because, as we have seen above, we have issues with the number of Wards and changes in boundaries across our three years, we will not (for now) complete any quantitative analysis of these population changes - this would require significant additional processing that we do not have time for today.
Note
Data interoperability is a key issue that you will face in spatial analysis, particularly when it comes to Administrative Geographies.
- Start QGIS. Let’s start a new project.
- Click on Project -> New. Save your project as
w2-pop-analysis. Remember to save your work throughout the practical. - Before we get started with adding data, we will first set the Coordinate Reference System of our Project. Click on Project -> Properties – CRS. In the Filter box, type British National Grid. Select OSGB 1936 / British National Grid - EPSG:27700 and click Apply. Click OK.
Note
We will explain CRSs and using CRSs in GIS software in more detail next week.
2.4.6.2 Adding layers
We will first focus on loading and joining the 2011 datasets.
Click on Layer -> Add Layer -> Add Vector Layer.
With File select as your source type, click on the small three dots button and navigate to your 2011 boundary files.
Here, we will select the
London_Ward.shpdataset. Click on the.shpfile of this dataset and click Open. Then click Add. You may need to close the box after adding the layer.
We can take a moment just to look at our Ward data - and recognise the shape of London. Can you see the City of London in the dataset? It has the smallest Wards in the entire London area. With the dataset loaded, we can now explore it in a little more detail. We want to check out two things about our data: first, its Properties and secondly, its Attribute Table.
- Right-click on the
London_Wardlayer and open the Attribute Table and look at how the attributes are stored and presented in the table. Explore the different buttons in the Attribute Table and see if you can figure out what they mean. Once done, close the Attribute Table. - Right-click on the
London_Wardlayer and select Properties. Click through the different tabs and see what they contain. Keep the Properties box open.
Before adding our population data, we can make a quick map of the Wards in London - we can add labels and change the symbolisation of our Wards.
In the Properties box, click on the Symbology tab - this is where we can change how our data layer looks. For example, here we can change the line and fill colour of our Wards utilising either the default options available or clicking on Simple Fill and changing these properties directly. Keep the overall styling to a Single Symbol for now - we will get back to this once we have added the population data. You can also click on the Labels tab - and set the Labels option to Single labels.
QGIS will default to the NAME column within our data. You can change the properties of these labels using the options available. Change the font to Futura and size 8 and under the add a small buffer to the labels by selecting Draw text bufer under the Buffer tab. You can click Apply to see what your labels look like. Please note that the background colour may differ.
Figure 2.4: It looks incredibly busy.
- Click OK once you are done changing the Symbology and Label style of your data to return to the main window.
Note
The main strength of a GUI GIS system is that is really helps us understand how we can visualise spatial data. Even with just these two shapefiles loaded, we can understand two key concepts of using spatial data within GIS.
The first, and this is only really relevant to GUI GIS systems, is that each layer can either be turned on or off, to make it visible or not (try clicking the tick box to the left of each layer). This is probably a feature you are used to working with if you have played with interactive web mapping applications before!
The second concept is the order in which your layers are drawn – and this is relevant for both GUI GIS and when using plotting libraries such as ggplot2 or tmap in RStudio. Your layers will be drawn depending on the order in which your layers are either tabled (as in a GUI GIS) or ‘called’ in your function in code.
Being aware of this need for ‘order’ is important when we shift to using RStudio and tmap to plot our maps, as if you do not layer your data correctly in your code, your map will end up not looking as you hoped!
For us using QGIS right now, the layers will be drawn from bottom to top. At the moment, we only have one layer loaded, so we do not need to worry about our order right now - but as we add in our 2015 and 2018 Ward files, it is useful to know about this order as we will need to display them individually to export them at the end.
2.4.6.3 Conducting an attribute join
We are now going to join our 2011 population data to our 2011 shapefile. First, we need to add the 2011 population data to our project.
Click on Layer -> Add Layer -> Add Delimited Text Layer.
Click on the three dots button again and navigate to your 2011 population data in your
workingfolder. Your file format should be set tocsv. You should have the following boxes clicked under the Record and Field options menu:Decimal separator is comma,First record has field names,Detect field typesandDiscard empty fields. QGIS does many of these by default, but do double-check!Set the Geometry to No geometry (attribute only table) under the Geometry Definition menu. Then click Add and Close. You should now see a table added to your
Layersbox.
We can now join this table data to our spatial data using an Attribute Join.
Note
An attribute join is one of two types of data joins you will use in spatial analysis (the other is a spatial join, which we will look at later on in the module). An attribute join essentially allows you to join two datasets together, as long as they share a common attribute to facilitate the ‘matching’ of rows:
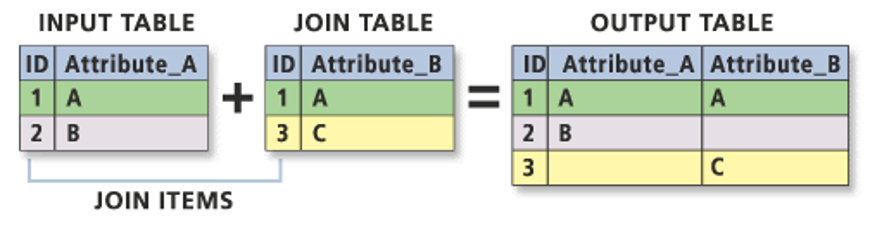
Essentially you need a single unique identifying ID field for your records within both datasets: this can be a code, a name or any other string of information. In spatial analysis, we always oin our table data to our shape data (One way to think about it as attaching the table data to each shape).
As a result, your target layer is always the shapefile (or spatial data) whereas your join layer is the table data. These are known as the left- and right-side tables when working with code.
To make a join work, you need to make sure your ID field is correct across both datasets, i.e. no typos or spelling mistakes. Computers can only follow instructions, so they do not know that St. Thomas in one dataset is that same as St Thomas in another, or even Saint Thomas! It will be looking for an exact match!
As a result, whilst in our datasets we have kept both the name and code for both the boundary data and the population data, when creating the join, we will always prefer to use the CODE over their names. Unlike names, codes reduce the likelihood of error and mismatch because they do not rely on understanding spelling!
Common errors, such as adding in spaces or using 0 instead O (and vice versa) can still happen – but it is less likely.
To make our join work, we need to check that we have a matching UID across both our datasets. We therefore need to look at the tables of both datasets and check what attributes we have that could be used for this possible match.
Open up the Attribute Tables of each layer and check what fields we have that could be used for the join. We can see that both our respective “code” fields have the same codes (
ward_codeandGSS_code) so we can use these to create our joins.Right-click on your
London_Wardlayer -> Properties and then click on the Joins tab.
- Click on the + button. Make sure the Join Layer is set to
ward_population_2011. - Set the Join field to
ward_code. - Set the Target field to
GSS_code. - Click the Joined Fields box and click to only select the
pop2011field. - Click on the Custom Field Name Prefix and remove the pre-entered text to leave it blank.
- Click on OK.
- Click on Apply in the main Join tab and then click OK to return to the main QGIS window.
We can now check to see if our join has worked by opening up our London_Ward Attribute Table and looking to see if our Wards now have a Population field attached to it.
- Right-click on the
London_Wardlayer and open the Attribute Table and check that the population data column has been added to the table.
As long as it has joined, you can move forward with the next steps. If your join has not worked, try the steps again - and if you are still struggling, do let us know.
Note
Now, the join that you have created between your Ward and population datasets in only held in QGIS’s memory. If you were to close the programme now, you would lose this join and have to repeat it the next time you opened QGIS. To prevent this from happening, we need to export our dataset to a new shapefile - and then re-add this to the map.
Let’s do this now:
- Right-click on your
London_Wardshapefile and click Export -> Save Features As…. The format should be set to an ESRI shapefile.
- Then click on the three dots buttons and navigate to your
outputfolder and enter:ward_population_2011as your file name. - Check that the CRS is British National Grid.
- Leave the remaining fields as selected, but check that the Add saved file to map is checked. Click OK.
You should now see our new shapefile add itself to our map. You can now remove the original London_Ward and ward_population_2011 datasets from our Layers box (Right-click on the layers and opt for Remove Layer…).
The final thing we would like to do with this dataset is to style our dataset by our newly added population field to show population distribution around London.
- To do this, again right-click on the Layer -> Properties -> Symbology.
- This time, we want to style our data using a Graduated symbology.
- Change this option in the tab and then choose
pop2011as your column. - We can then change the color ramp to suit our aesthetic preferences - Viridis seems to be the cool colour scheme at the moment, and we will choose to invert our ramp as well.
- The final thing we need to do is classify our data - what this simply means is to decide how to group the values in our dataset together to create the graduated representation.
- We will be looking at this in later weeks, but for now, we will use the Natural Breaks option.
- Click on the drop-down next to Mode, select Natural Breaks, change it to 7 classes and then click Classify.
- Finally click Apply to style your dataset.
Tip
Understanding what classification is appropriate to visualise your data is an important step within spatial analysis and visualisation, and something you will learn more about in the following weeks. Overall, they should be determined by understanding your data’s distribution and match your visualisation accordingly.
Feel free to explore using the different options with your dataset at the moment – the results are almost instantaneous using QGIS, which makes it a good playground to see how certain parameters or settings can change your output.
You should now be looking at something like this:
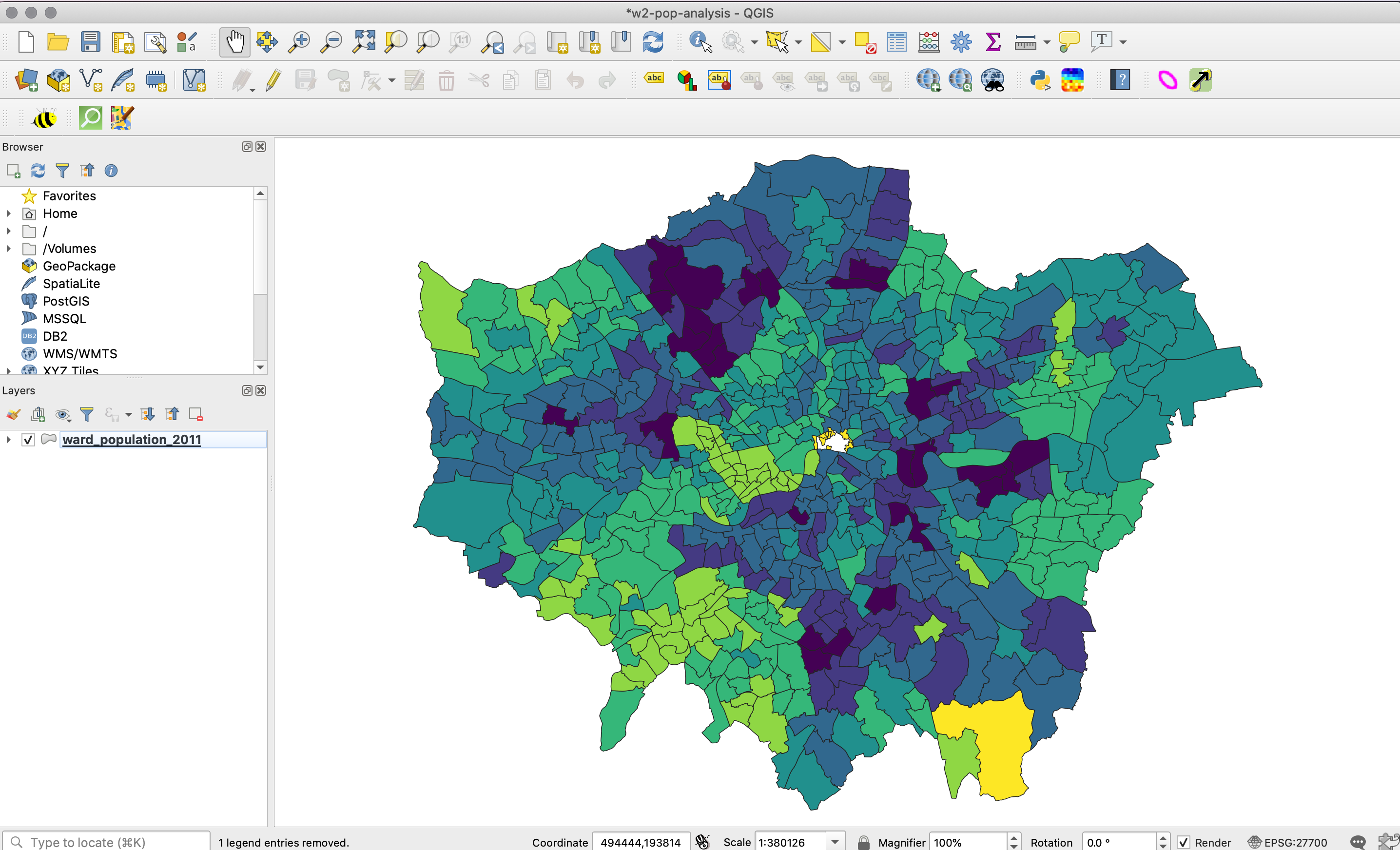
Figure 2.5: Your result.
You will be able to see that we have some missing data - and this is for several Wards within the City of London. This is because census data is only recorded for 8 out of the 25 Wards and therefore we have no data for the remaining Wards. As a result, these Wards are left blank, i.e. white, to represent a NODATA value.
Note
One thing to flag is that NODATA means no data - whereas 0, particularly in a scenario like this, would be an actual numeric value. It is important to remember this when processing and visualising data, to make sure you do not represent a NODATA value incorrectly.
2.4.7 Exporting map for visual analysis
To export your map select only the map layers you want to export and then opt for Project -> Import/Export -> Export to Image and save your final map in your maps folder. You may want to create a folder for these maps titled w02.
Next week, we will look at how to style our maps using the main map conventions (adding North Arrows, Scale Bars and Legends) but for now a simple picture will do.
2.5 Assignment
You now need to repeat the entire process for your 2015 and 2019 datasets. Remember, you need to:
- Load the respective Ward dataset as a Vector Layer.
- Load the respective Population dataset as a Delimited Text File Layer (remember the settings!).
- Join the two datasets together using the Join tool in the Ward dataset Properties box.
- Export your joined dataset into a new dataset within your
outputfolder. - Style your data appropriately.
- Export your maps as an image to your
mapsfolder.
To make visual comparisons against our three datasets, theoretically we would need to standardise the breaks at which our classification schemes are set at. To set all three datasets to the same breaks, you can do the following:
- Right-click on the
ward_population_2019dataset and navigate to theSymbologytab. Double-click on the Values for the smallest classification group and set the Lower value to 141 (this is the lowest figure across our datasets, found in the 2015 data). Click OK, then click Apply, then click OK to return to the main QGIS screen. - Right-click again on the
ward_population_2019dataset but this time, click on Styles -> Copy Styles -> Symbology. - Now right-click on the
ward_population_2015file, but this time after clicking on Styles -> Paste Style -> Symbology. You should now see the classification breaks in the 2015 dataset change to match those in the 2019 data. - Repeat this for the 2011 dataset as well.
- The final thing you need to do is to now change the classification column in the
Symbologytab for the 2015 and 2011 datasets back to their original columns and press Apply. You will see when you first load up their Symbology options this is set to pop2019, which of course does not exist within this dataset.
2.6 Before you leave
Save your project so you can go back to it if you need to, other than that that is it for this week!