This week we will turn to geodemographic classification. Geodemographic classification is a method used to categorise geographic areas and the people living in them based on demographic, socioeconomic, and sometimes lifestyle characteristics. This approach combines geographic information with demographic data to create profiles of different neighborhoods.
Lecture slides
You can download the slides of this week’s lecture here: [Link].
Reading list
Essential readings
Longley, P. A. 2012. Geodemographics and the practices of geographic information science. International Journal of Geographical Information Science 26(12): 2227-2237. [Link]
Singleton, A. and Longley, P. A. 2024. Classifying and mapping residential structure through the London Output Area Classification. Environment and Planning B: Urban Analytics and City Science 51(5): 1153-1164. [Link]
Wyszomierski, J., Longley, P. A., and Singleton, A. et al. 2024. A neighbourhood Output Area Classification from the 2021 and 2022 UK censuses. The Geographical Journal. 190(2): e12550. [Link]
Suggested readings
Dalton, C. M. and Thatcher. J. 2015. Inflated granularity: Spatial “Big Data” and geodemographics. Big Data & Society 2(2): 1-15. [Link]
Fränti, P. and Sieronoja, S. 2019. How much can k-means be improved by using better initialization and repeats? Pattern Recognition 93: 95-112. [Link]
Singleton, A. and Spielman, S. 2014. The past, present, and future of geodemographic research in the United States and United Kingdom. The Professional Geographer 66(4): 558-567. [Link]
Classifying London
Today, we will create our own geodemographic classification to examine demographic clusters across London, drawing inspiration from London Output Area Classification. Specifically, we will try to identify clusters based on age group, self-identified ethnicity, country of birth, and first or preferred language.
The data covers all usual residents, as recorded in the 2021 Census for England and Wales, aggregated at the Lower Super Output Area (LSOA) level. These datasets have been extracted using the Custom Dataset Tool, and you can download each file via the links provided below. A copy of the 2021 London LSOAs spatial boundaries is also available. Save these files in your project folder under data.
To download a csv file that is hosted on GitHub, click on the Download raw file button on the top right of your screen and it should download directly to your computer.
For the spatial boundaries of the London LSOAs, you may have noticed that, instead of providing a collection of files known as a shapefile, we have supplied a GeoPackage. While shapefiles remain in use, GeoPackage is a more modern and portable file format. Have a look at this article on towardsdatascience.com for an excellent explanation on why one should use GeoPackage files over shapefiles, where possible: [Link]
Open a new script and save this as w07-geodemographic-analysis.r.
You may have to install some of these libraries if you have not used these before.
Next, we can load the individual csv files that we downloaded into R.
R code
# load age datalsoa_age <-read_csv("data/London-LSOA-AgeGroup.csv")
Rows: 24970 Columns: 5
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): Lower layer Super Output Areas Code, Lower layer Super Output Areas...
dbl (2): Age (5 categories) Code, Observation
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
# load country of birth datalsoa_cob <-read_csv("data/London-LSOA-Country-of-Birth.csv")
Rows: 39952 Columns: 5
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): Lower layer Super Output Areas Code, Lower layer Super Output Areas...
dbl (2): Country of birth (8 categories) Code, Observation
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 99880 Columns: 5
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): Lower layer Super Output Areas Code, Lower layer Super Output Areas...
dbl (2): Ethnic group (20 categories) Code, Observation
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
# load language datalsoa_lan <-read_csv("data/London-LSOA-MainLanguage.csv")
Rows: 54934 Columns: 5
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): Lower layer Super Output Areas Code, Lower layer Super Output Areas...
dbl (2): Main language (11 categories) Code, Observation
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
If using a Windows machine, you may need to substitute your forward-slashes (/) with two backslashes (\\) whenever you are dealing with file paths.
Now, carefully examine each individual dataframe to understand how the data is structured and what information it contains.
R code
# inspect age datahead(lsoa_age)
# A tibble: 6 × 5
Lower layer Super Output Areas…¹ Lower layer Super Ou…² Age (5 categories) C…³
<chr> <chr> <dbl>
1 E01000001 City of London 001A 1
2 E01000001 City of London 001A 2
3 E01000001 City of London 001A 3
4 E01000001 City of London 001A 4
5 E01000001 City of London 001A 5
6 E01000002 City of London 001B 1
# ℹ abbreviated names: ¹`Lower layer Super Output Areas Code`,
# ²`Lower layer Super Output Areas`, ³`Age (5 categories) Code`
# ℹ 2 more variables: `Age (5 categories)` <chr>, Observation <dbl>
# inspect country of birth datahead(lsoa_cob)
# A tibble: 6 × 5
Lower layer Super Output Areas…¹ Lower layer Super Ou…² Country of birth (8 …³
<chr> <chr> <dbl>
1 E01000001 City of London 001A -8
2 E01000001 City of London 001A 1
3 E01000001 City of London 001A 2
4 E01000001 City of London 001A 3
5 E01000001 City of London 001A 4
6 E01000001 City of London 001A 5
# ℹ abbreviated names: ¹`Lower layer Super Output Areas Code`,
# ²`Lower layer Super Output Areas`, ³`Country of birth (8 categories) Code`
# ℹ 2 more variables: `Country of birth (8 categories)` <chr>,
# Observation <dbl>
# inspect ethnicity datahead(lsoa_eth)
# A tibble: 6 × 5
Lower layer Super Output Areas…¹ Lower layer Super Ou…² Ethnic group (20 cat…³
<chr> <chr> <dbl>
1 E01000001 City of London 001A -8
2 E01000001 City of London 001A 1
3 E01000001 City of London 001A 2
4 E01000001 City of London 001A 3
5 E01000001 City of London 001A 4
6 E01000001 City of London 001A 5
# ℹ abbreviated names: ¹`Lower layer Super Output Areas Code`,
# ²`Lower layer Super Output Areas`, ³`Ethnic group (20 categories) Code`
# ℹ 2 more variables: `Ethnic group (20 categories)` <chr>, Observation <dbl>
# inspect language datahead(lsoa_lan)
# A tibble: 6 × 5
Lower layer Super Output Areas…¹ Lower layer Super Ou…² Main language (11 ca…³
<chr> <chr> <dbl>
1 E01000001 City of London 001A -8
2 E01000001 City of London 001A 1
3 E01000001 City of London 001A 2
4 E01000001 City of London 001A 3
5 E01000001 City of London 001A 4
6 E01000001 City of London 001A 5
# ℹ abbreviated names: ¹`Lower layer Super Output Areas Code`,
# ²`Lower layer Super Output Areas`, ³`Main language (11 categories) Code`
# ℹ 2 more variables: `Main language (11 categories)` <chr>, Observation <dbl>
You can further inspect the results using the View() function.
Variable preparation
To identify geodemographic clusters in our dataset, we will use a technique called \(k\)-means. \(k\)-means aims to partition a set of standardised observations into a specified number of clusters (\(k\)). To do this we first need to prepare the individual datasets, as well as transform and standardise the input variables.
\(k\)-means clustering is an unsupervised machine learning algorithm used to group data into a predefined number of clusters, based on similarities between data points. It works by initially assigning \(k\) random centroids, then iteratively updating them by assigning each data point to the nearest centroid and recalculating the centroid’s position based on the mean of the points in each cluster. The process continues until the centroids stabilise, meaning they no longer change significantly. \(k\)-means is often used for tasks such as data segmentation, image compression, or anomaly detection. It is simple but may not work well with non-spherical or overlapping clusters.
Because all the data are stored in long format, with each London LSOA appearing on multiple rows for each category — such as separate rows for different age groups, ethnicities, countries of birth, and first or preferred languages - we need to transform it into a wide format. For example, instead of having multiple rows for an LSOA showing counts for different age groups all the information for each LSOA will be consolidated into a single row. Additionally, we will clean up the column names to follow standard R naming conventions and make the data easier to work with. We can automate this process using the janitor package.
The code above uses a pipe function: |>. The pipe operator allows you to pass the output of one function directly into the next, streamlining your code. While it might be a bit confusing at first, you will find that it makes your code faster to write and easier to read. More importantly, it reduces the need to create multiple intermediate variables to store outputs.
To account for the non-uniformity of the areal units, we further need to convert the observations to proportions and only retain those columns that are likely to be meaningful in the context of the classification:
R code
# total observationslsoa_age <- lsoa_age |>rowwise() |>mutate(age_pop =sum(across(2:6)))# total proportions, select columnslsoa_age <- lsoa_age |>mutate(across(2:6, ~./age_pop)) |>select(1:6)# inspecthead(lsoa_age)
We now have four separate datasets, each containing the proportions of usual residents classified into different groups based on age, country of birth, ethnicity, and language.
Variable selection
Where we initially selected variables from different demographic domains, not all variables may be suitable for inclusion. Firstly, the variables need to exhibit sufficient heterogeneity to ensure they capture meaningful differences between observations. Secondly, variables should not be highly correlated with one another, as this redundancy can skew the clustering results. Ensuring acceptable correlation between variables helps maintain the diversity of information and improves the robustness of the clustering outcome.
Variable selection is often a time-consuming process that requires a combination of domain knowledge and more extensive exploratory analysis than is covered in this practical.
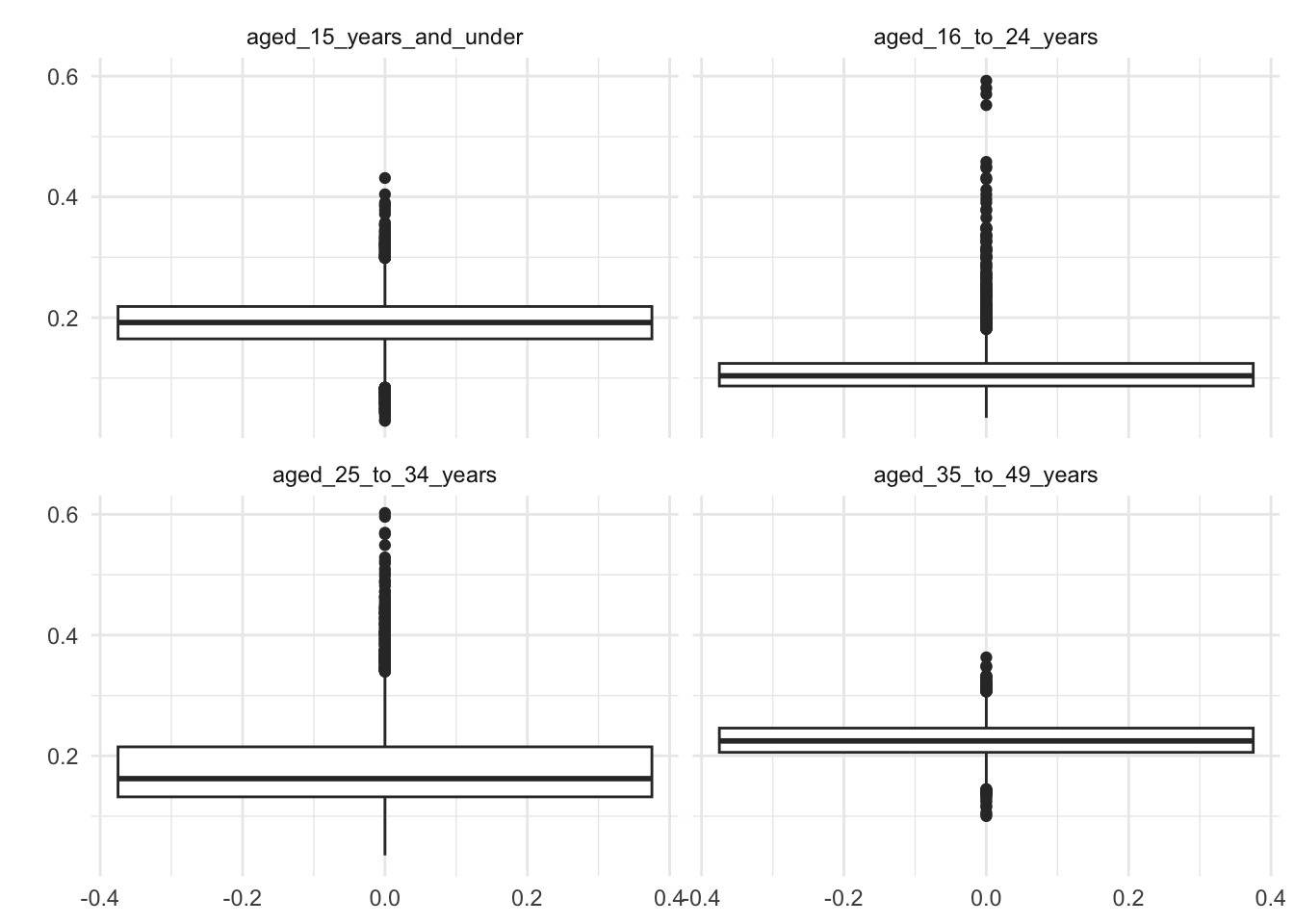
A straightforward yet effective method to examine the distribution of our variables is to create boxplots for each variable. This can be efficiently achieved by using facet_wrap() from the ggplot2 library to generate a matrix of panels, allowing us to visualise all variables in a single view.
ggplot2 is a popular data visualisation package in R, designed for creating complex plots. It uses the Grammar of Graphics to build layered, customisable graphics by mapping data to visual elements like colour, size, and shape. You can refer to the ggplot2 documentation for more details.
Figure 1: Boxplots of the distribution of the age dataset.
When repeating this process for the birth, ethnicity, and language variables, you will notice that some variables have a very limited distribution. Specifically, some variables may have a value of 0 for the majority of London LSOAs. As a rule of thumb, we will retain only those variables where at least 75% of the LSOAs have values different from 0.
This threshold of 75% is arbitrary, and in practice, more thorough consideration should be given when deciding whether to include or exclude a variable.
R code
# joinlsoa_df <- lsoa_age |>left_join(lsoa_cob, by ="lower_layer_super_output_areas_code") |>left_join(lsoa_eth, by ="lower_layer_super_output_areas_code") |>left_join(lsoa_lan, by ="lower_layer_super_output_areas_code")# calculate proportion of zeroeszero_prop <-sapply(lsoa_df[2:41], function(x) {mean(x ==0)})# extract variables with high proportion zeroesidx <-which(zero_prop >0.25)# inspectidx
# remove variables with high proportion zeroeslsoa_df <- lsoa_df |>select(-white_gypsy_or_irish_traveller, -any_other_uk_languages, -oceanic_or_australian_languages,-north_or_south_american_languages)
The code above makes use of Boolean logic to calculate the proportion of zeroes within each variable. The x == 0 part checks each value in column x to see if it is equal to 0, returning TRUE or FALSE for each element. The mean() function is then used to calculate the average of the TRUE values in the column. Since TRUE is treated as 1 and FALSE as 0, this gives the proportion of values in the column that are equal to zero.
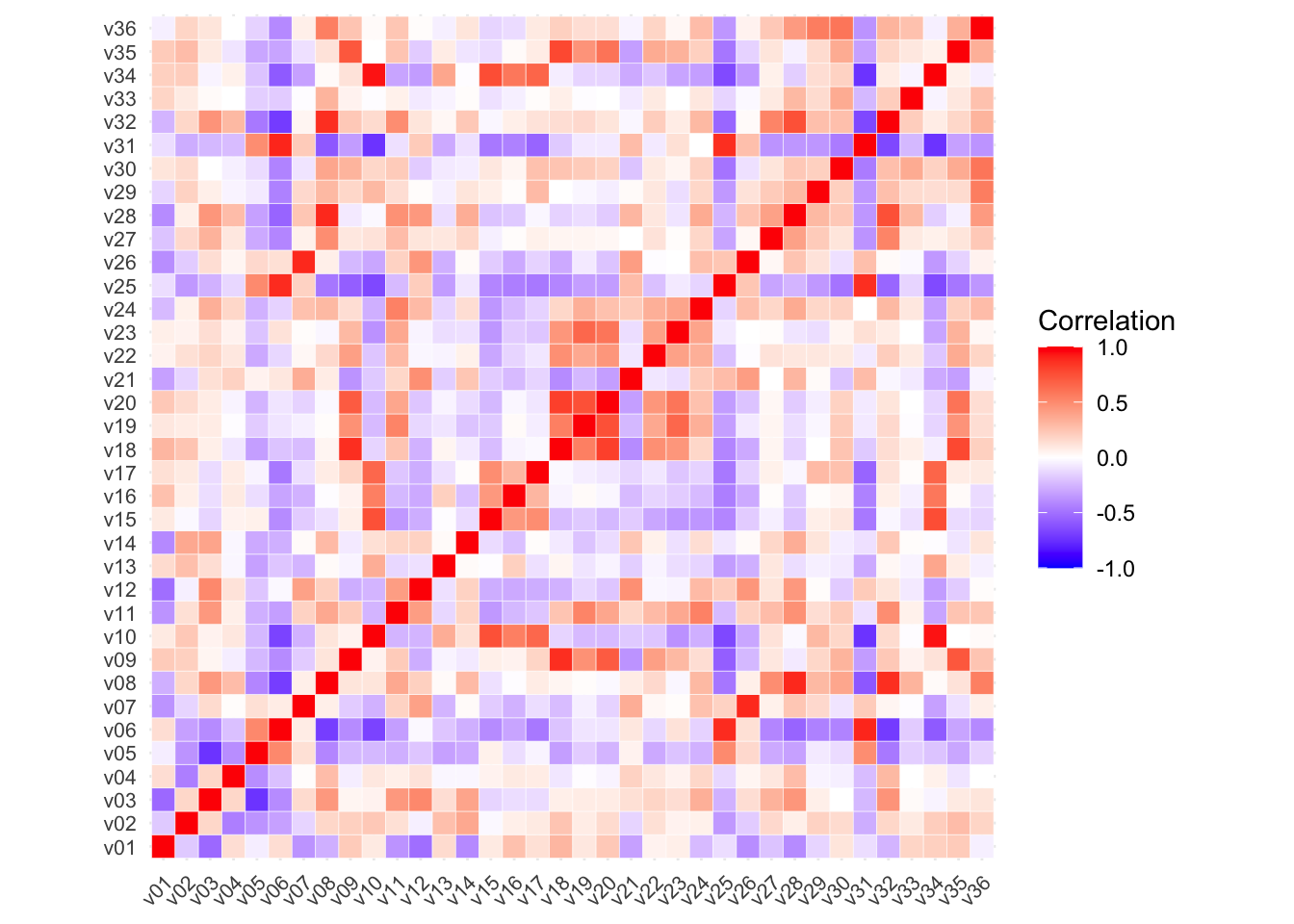
We can subsequently check for multicollinearity of the remaining variables. The easiest way to check the correlations between all variables is probably by visualising a correlation matrix:
# change variable names to index to improve visualisationlsoa_df_vis <- lsoa_dfnames(lsoa_df_vis)[2:37] <-paste0("v", sprintf("%02d", 1:36))# correlation matrixcor_mat <-cor(lsoa_df_vis[, -1])# correlation plotggcorrplot(cor_mat, outline.col ="#ffffff", tl.cex =8, legend.title ="Correlation")
Figure 2: Correlation plot of classification variables.
Following the approach from Wyszomierski et al. (2024), we can define a weak correlation as lying between 0 and 0.40, moderate as between 0.41 and 0.65, strong as between 0.66 and 0.80, and very strong as between 0.81 and 1.
A few strong and very strong correlations can be observed that potentially could be removed; however, to maintain representation, here we decide to retain all variables.
Variable standardisation
If the input data are heavily skewed or contain outliers, \(k\)-means may produce less meaningful clusters. While normality is not required per se, it has been common to do this nonetheless. More important is to standardise the input variables, especially when they are measured on different scales. This ensures that each variable contributes equally to the clustering process.
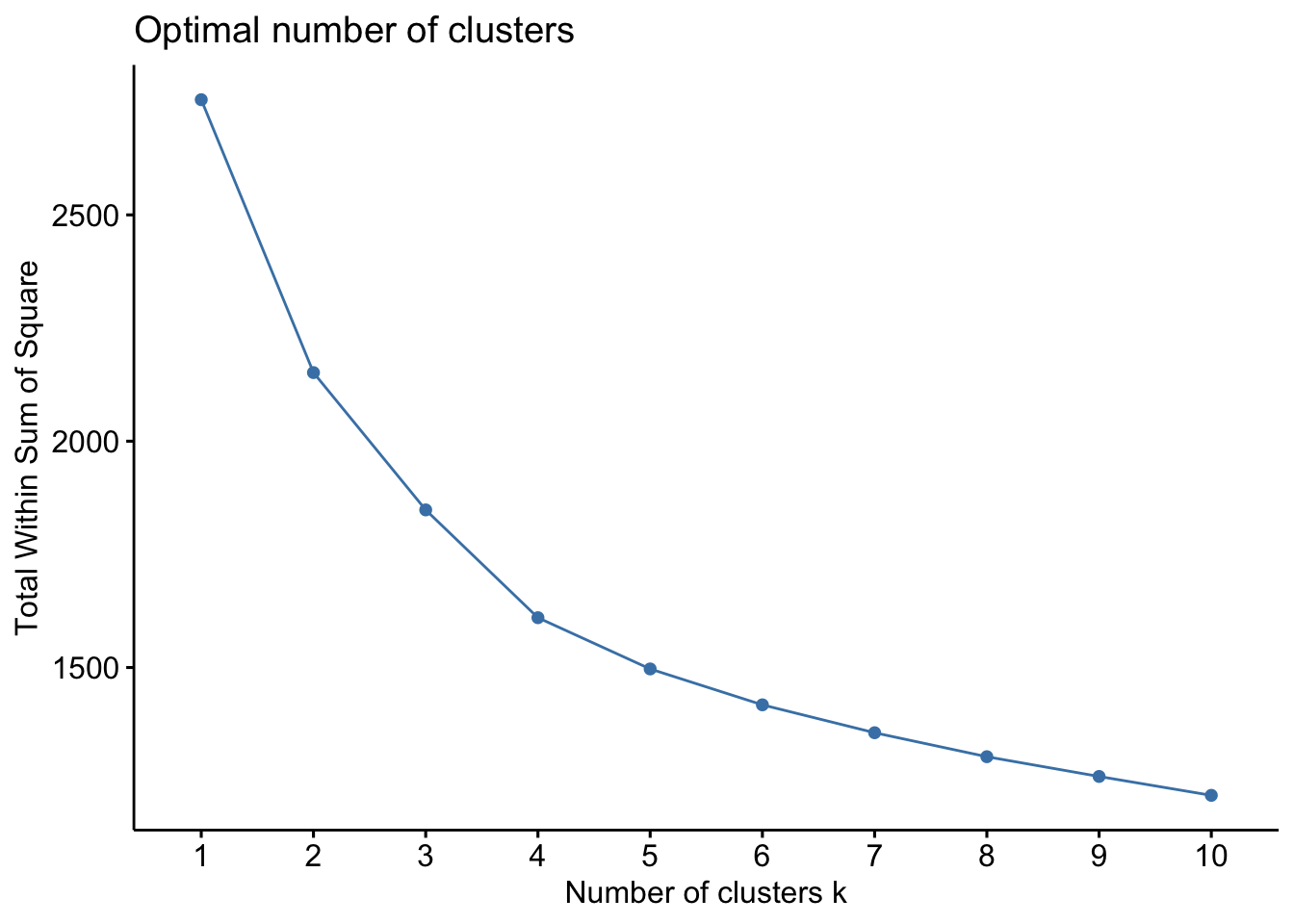
Now our data are prepared we will start by creating an elbow plot. The elbow method is a visual tool that helps determine the optimal number of clusters in a dataset. This is important because with \(k\)-means clustering you need to specify the numbers of clusters a priori. The elbow method involves running the clustering algorithm with varying numbers of clusters (\(k\)) and plotting the total explained variation (known as the Within Sum of Squares) against the number of clusters. The goal is to identify the ‘elbow’ point on the curve, where the rate of decrease in explained variation starts to slow. This point suggests that adding more clusters yields diminishing returns in terms of explained variation.
Figure 3: Elbow plot with ‘Within Sum of Squares’ against number of clusters.
Based on the elbow plot, we can now choose the number of clusters and it looks like 6 clusters would be a reasonable choice.
The interpretation of an elbow plot can be quite subjective, and multiple options for the optimal number of clusters might be justified; for instance, 4, 5, or even 7 clusters could be reasonable choices. In addition to the elbow method, other techniques can aid in determining the optimal number of clusters, such as silhouette scores and the gap statistic. An alternative and helful approach is to use a clustergram, which is a two-dimensional plot that visualises the flows of observations between clusters as more clusters are added. This method illustrates how your data reshuffles with each additional cluster and provides insights into the quality of the splits. This method can be done in R, but currently easier to implement in Python.
\(k\)-means clustering
Now we have decided on the number of clusters, we can run our \(k\)-means analysis.
R code
# set seed for reproducibilityset.seed(999)# k-meanslsoa_clus <-kmeans(lsoa_df_vis[, -1], centers =6, nstart =100, iter.max =100)
We can inspect the object to get some information about our clusters:
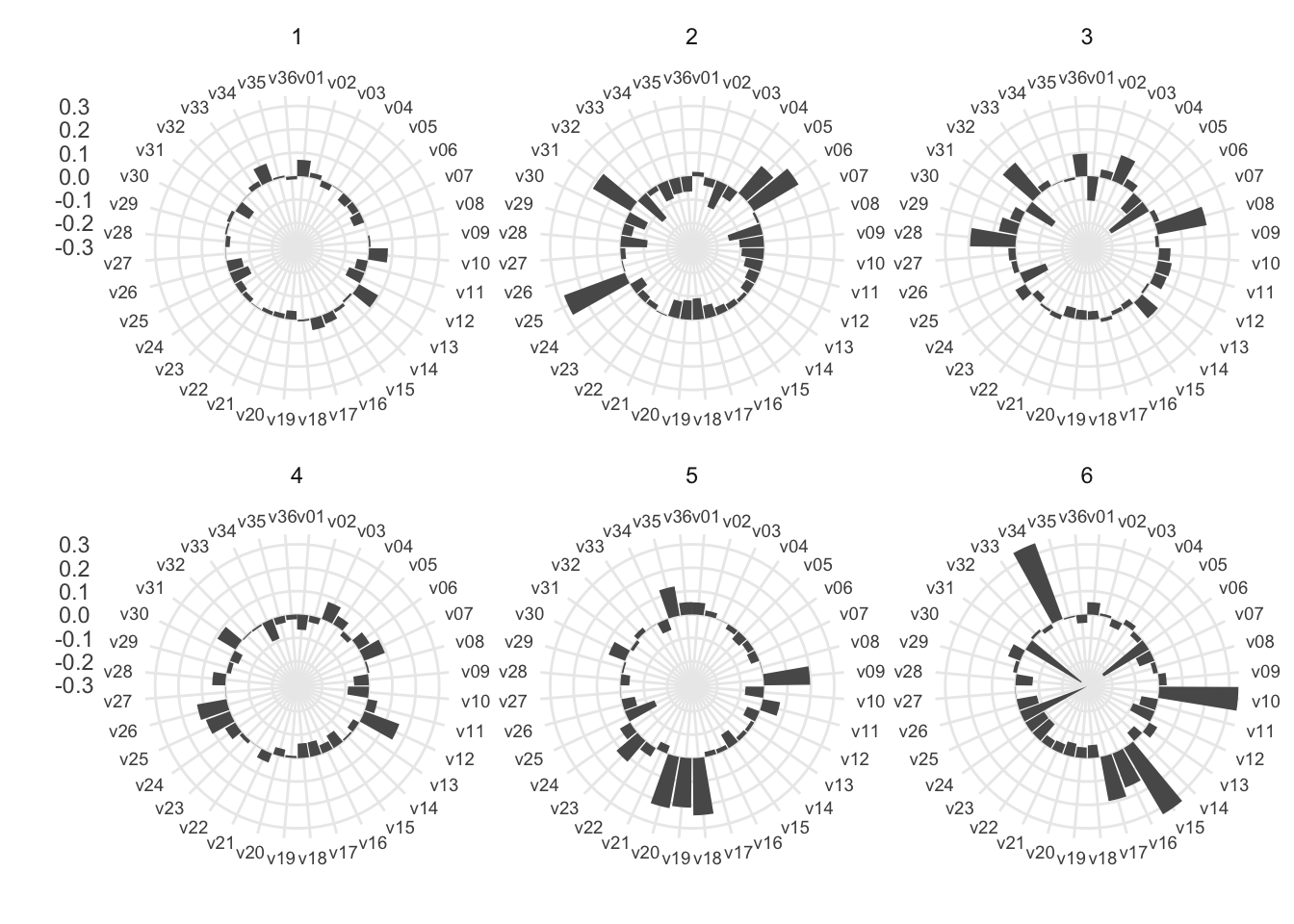
We now need to perform some post-processing to extract useful summary data for each cluster. To characterise the clusters, we can compare the global mean values of each variable with the mean values specific to each cluster.
Figure 4: Radial barplots of cluster means for each input variable.
These plots can serve as a foundation for creating pen portraits by closely examining which variables drive each cluster.
For easier interpretation, these values can be transformed into index scores, allowing us to assess which variables are under- or overrepresented within each cluster group.
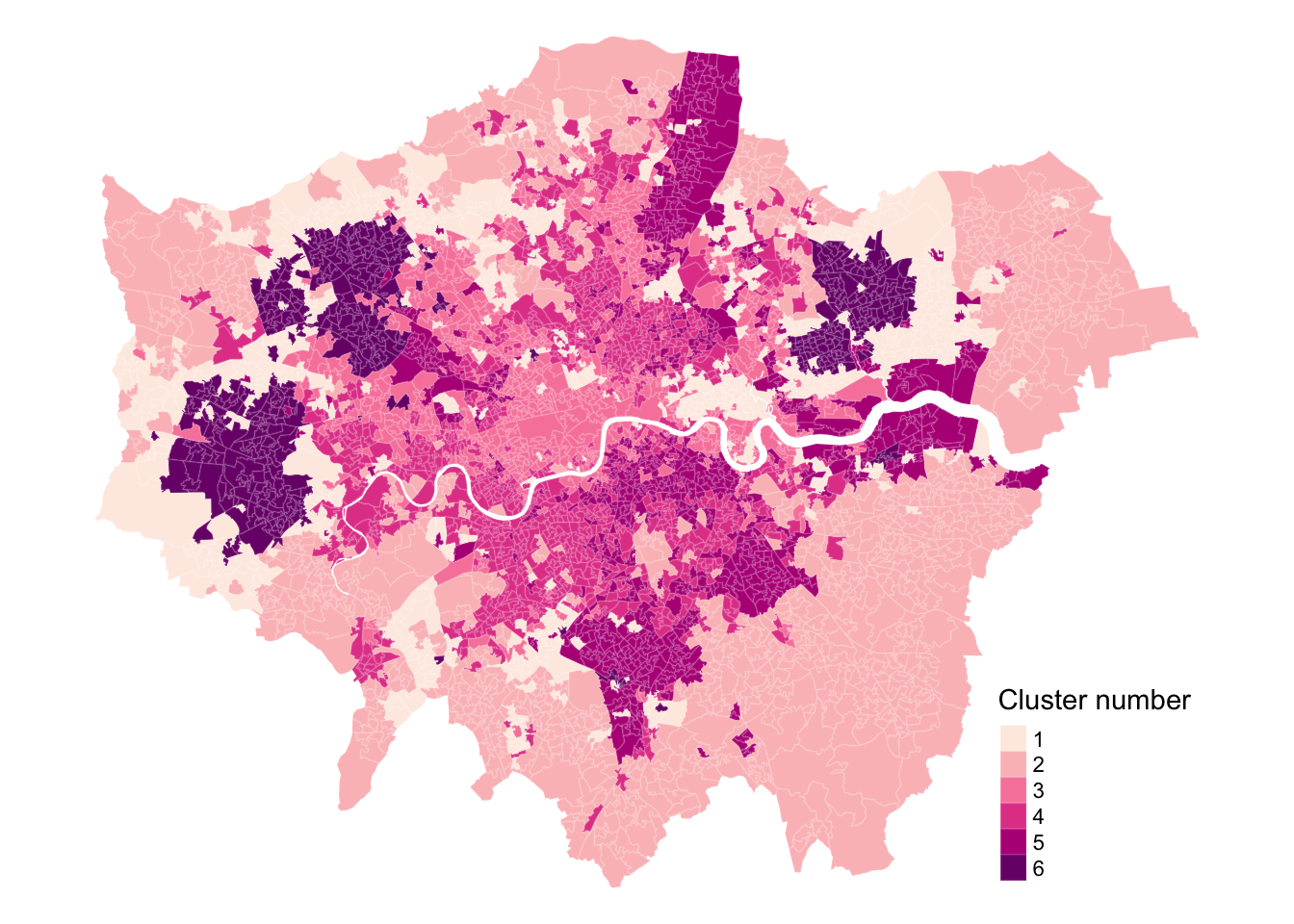
Figure 5: Classification of London LSOAs based on several demographic variables.
Assignment
The creation of a geodemographic classification is an iterative process. This typically includes adding or removing variables, adjusting the number of clusters, and grouping data in different ways to achieve the most meaningful segmentation. Try to do the following:
Download the two datasets provided below and save them to your data folder. The datasets include:
A csv file containing the number of people aged 16 years and older by occupational category, as defined by the Standard Occupational Classification 2020, aggregated by 2021 LSOAs.
A csv file containing the number of people aged 16 years and older by their highest level of qualification, also aggregated to the 2021 LSOA level.
Prepare these two datasets and retain only those variables that are potentially meaningful. Filter out any variables with a high proportion of zero values.
Merge the education and occupation dataset with the dataset used to generate the initial geodemographic classification. Check for multicollinearity and consider removing any variables that are highly correlated.
Perform \(k\)-means clustering on your extended dataset. Make sure to select an appropriate number of clusters for your analysis.
Interpret the individual clusters in terms of the variables that are under- and overrepresented.